

Семантичне ядро – це та база, на основі якої будується вся робота по створенню та просуванню сайту. Якщо спочатку створити сайт, а потім збирати ключі, швидше за все ви будете його переробляти. Якщо зробити збір СЯ неправильно та почати просування, переробляти доведеться майже все. Тому краще не довіряти цей процес нікому, а робити самостійно.
Для прикладу – я збираю семантику вже 16 років, для всіх клієнтських та особистих проектів. І у мене немає бажання передати її на аутсорс. Тому що:
- Якщо семантик просто пропустить частину важливих ключів – це ще куди не йшло. Хоч і не дуже приємно просувати сайт півроку, а потім отримавши від клієнта питання «чому ми не опрацьовуємо запити такі-то» не знати, що відповісти.
- Якщо семантик включить в одну групу запити, за якими результати пошуку кардинально відрізняються, ви просто не зможете просунути одну сторінку по всій групі. І потім доведеться створювати нові сторінки. А це сильно збільшить термін просування, і багато замовників не стануть стільки чекати.
- Якщо семантик зробить неправильне розгрупування, і ви цього відразу не побачите, є всі шанси, що структуру сайту доведеться переробляти. Питання тільки в тому, наскільки далеко ви встигнете зайти з неправильною структурою.
І це тільки частина проблем. Можна навести ще багато «якщо» та підтвердити їх прикладами. За роки роботи їх набралося в надлишку. Але не будемо затягувати статтю. Давайте розбиратися, як правильно підбирати ключові слова, щоб потім не довелося переробляти ні сайт, ні оптимізацію, не кажучи вже про саме семантичне ядро.
Терміни та визначення
Для початку розберемося, що таке ключові слова, семантичне ядро сайту та частота пошукового запиту. Тільки не стандартні визначення, який сенс писати те, що вже сотні разів написано, а простими словами, щоб був зрозумілий зміст.
Ключове слово – це те слово або фраза, яку користувач вбиває в пошуковий рядок. Наприклад, ви хочете замовити новий телефон. Відкриваєте браузер і в пошуковий рядок Google або в адресний рядок пишете «купити iphone». Це і є ключове слово. Називають його по-різному: пошуковий запит, ключова фраза, ключовий запит, ключ.
Семантичне ядро сайту (СЯ) – це список усіх пошукових запитів, за якими він просувається. Наприклад, візьмемо агентство PROSUVER і уявімо, що ми надаємо тільки 3 послуги: SEO-просування, консультації, аудити. Якщо підібрати для кожної ключі і об’єднати в один список – це і буде СЯ для просування даного сайту.
Приклад семантичного ядра сайту в Excel:
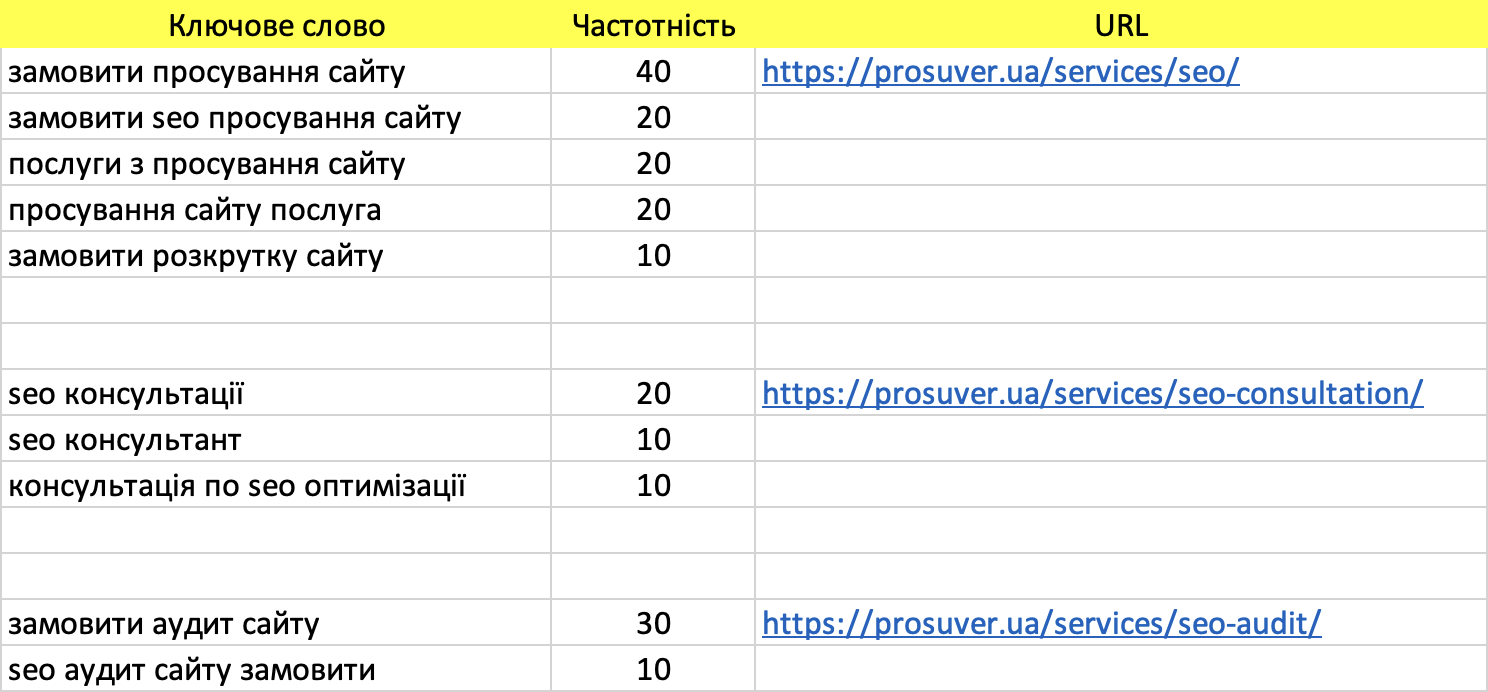
Кластеризація семантичного ядра – це коли з одного великого списку ключових слів роблять невеликі групи і розподіляють їх по посадочних сторінках. На практиці це виглядає так – ви зібрали, скажімо, 500 пошукових фраз, після очищення їх залишилося 350. Всі вони потенційно підходять для просування вашого проекту, але ви не можете просувати під них тільки одну сторінку. Логічно ж, що користувачі, які шукають аудит і консультацію, повинні бачити різні сторінки. Відповідно вам потрібно кластеризувати запити – розподілити їх по різних групах. На скріншоті вище показано, як це виглядає.
Посадкова сторінка – це будь-яка сторінка, для якої відібрані пошукові запити і яка бере участь у просуванні. Тобто, у вас може бути сайт на 100 сторінок, але ключі ви підібрали тільки для 5 розділів та 10 товарів/послуг і намагаєтеся просунути їх. Так ось посадочних у вас буде всього 15, а не 100.
Частота ключової фрази (частотність) – це те, скільки разів на місяць дану пошукову фразу вбивали в пошуковий рядок. У нашому випадку мова буде йти про пошуковий рядок Google та частотність будемо знімати для нього.
Збір семантичного ядра – це підбір ключових слів для всього сайту, їх очищення, кластеризація і розподіл по посадочних сторінках.
Види пошукових запитів
Якщо вам потрібно правильно зібрати семантичне ядро для єдиного проекту і більше ви цим займатися не плануєте, цю частину можна пропустити. Але якщо плануєте розвиватися як фахівець в SEO або семантик, розібратися доведеться. Тому що часто буде траплятися ось таке: «ВЧ ВК запити», «ключі СЧ НК».
За популярністю
- Високочастотні (ВЧ).
- Середньочастотні (СЧ).
- Низькочастотні (НЧ).
Як це виглядає в теорії. Деякі автори статей наводять цифри, які теоретично повинні допомогти вам визначити, до якої групи належить той чи інший ключ. Наприклад, більше 10 000 показів на місяць – це ВЧ, від 1000 до 10 000 – СЧ, менше 1000 – НЧ. Але це просто середні значення без прив’язки до конкретної ситуації. Яка вам різниця, що монітор в середньому коштує 500$, якщо ви собі будете купувати за 200$ або 1000$?
Як це виглядає на практиці. Цифри, які дозволяють віднести ключ до ВЧ, СЧ або НЧ індивідуальні для кожної тематики. Наприклад, ви просуваєте невеликий бізнес з регулювання пластикових вікон в Києві. Найчастіший ключ буде мати 480 показів на місяць. Так ось, в даній конкретній ніші це і буде ВЧ. Відповідно СЧ – це все, що нижче його, але більше хоча б 100 показів на місяць. А НЧ – менше 100.
Такий підхід набагато зручніший та практичніший. Тому що, якщо слідувати теорії, тоді вся ваша семантика складається з одних НЧ. Але розподіл за частотністю важливий не заради абсолютних цифр, а для того, щоб виділити в конкретній ніші найбільш та найменш важливі пошукові фрази. Якщо цього не зробити, тоді вийде, що:
регулювання пластикових вікон
ремонт регулювання пластикових вікон
Рівнозначні. Але у першого частота 480 показів, а у другого 10. І якщо ми обидва віднесемо до НЧ та будемо виділяти однакові зусилля на просування, то другий вийде в ТОП досить швидко, але не буде давати трафіку, там його просто немає. А для першого нам не вистачить виділених ресурсів, він не стане в ТОП 1-3 і не буде давати трафіку, хоча потенціал у нього якраз є.
Щоб уникнути таких ситуацій – в кожній ніші визначається своя межа для ВЧ і від неї вже приблизно визначаємо цифри для СЧ та НЧ.
За змістом
- Комерційні.
- Інформаційні.
- Змішані (загальні).
- Навігаційні.
З навігаційними найпростіше – це запити, за якими користувач шукає не просто інформацію або послугу, а хоче потрапити на конкретний сайт. Наприклад: «як правильно скласти семантичне ядро prosuver». У даному прикладі користувача цікавить не відповідь на питання в цілому, йому потрібна стаття саме в блозі PROSUVER. Можливо, він читав її раніше і тепер хоче прочитати ще раз.
Для SEO такі ключі майже марні. Вони стануть в ТОП самі, спеціально працювати з ними не потрібно. Звичайно, є винятки, але це окрема тема і вони не так часто зустрічаються в роботі SEO-шника, щоб розписувати їх тут. Тому, практично у всіх випадках такі фрази прибирають із семантичного ядра.
Комерційні ключові слова – це фрази, за якими відразу видно, що користувач хоче щось купити. Приклад: купити телефон, натяжні стелі ціна. Якщо потрібно скласти семантичне ядро для інтернет-магазину або сайту з послугами – відбираєте саме їх.
Інформаційні ключові слова – це фрази, за якими користувач шукає інформацію. Приклад: що таке семантика сайту. Відбираєте їх, якщо робите ядро для блогу або будь-якого інформаційного проекту.
В принципі, все логічно і не потрібно було б пояснень, якби не запити, за якими результати пошуку змішані. Тобто, в них є і комерційні сайти, і інформаційні. Проблема в тому, що новачки часто не можуть зрозуміти, до яких груп їх включати.
Наприклад, візьмемо 3 фрази:
виведення з-під фільтра замовити
як вивести сайт з-під фільтра своїми руками
виведення з-під фільтра
Перший – комерційний і для нього повинна бути сторінка послуг. Другий – інформаційний і для просування по ньому потрібна стаття в блозі. Третій – не зрозуміло, користувачеві потрібна інформація або послуга. І результати пошуку за такими ключами змішані:
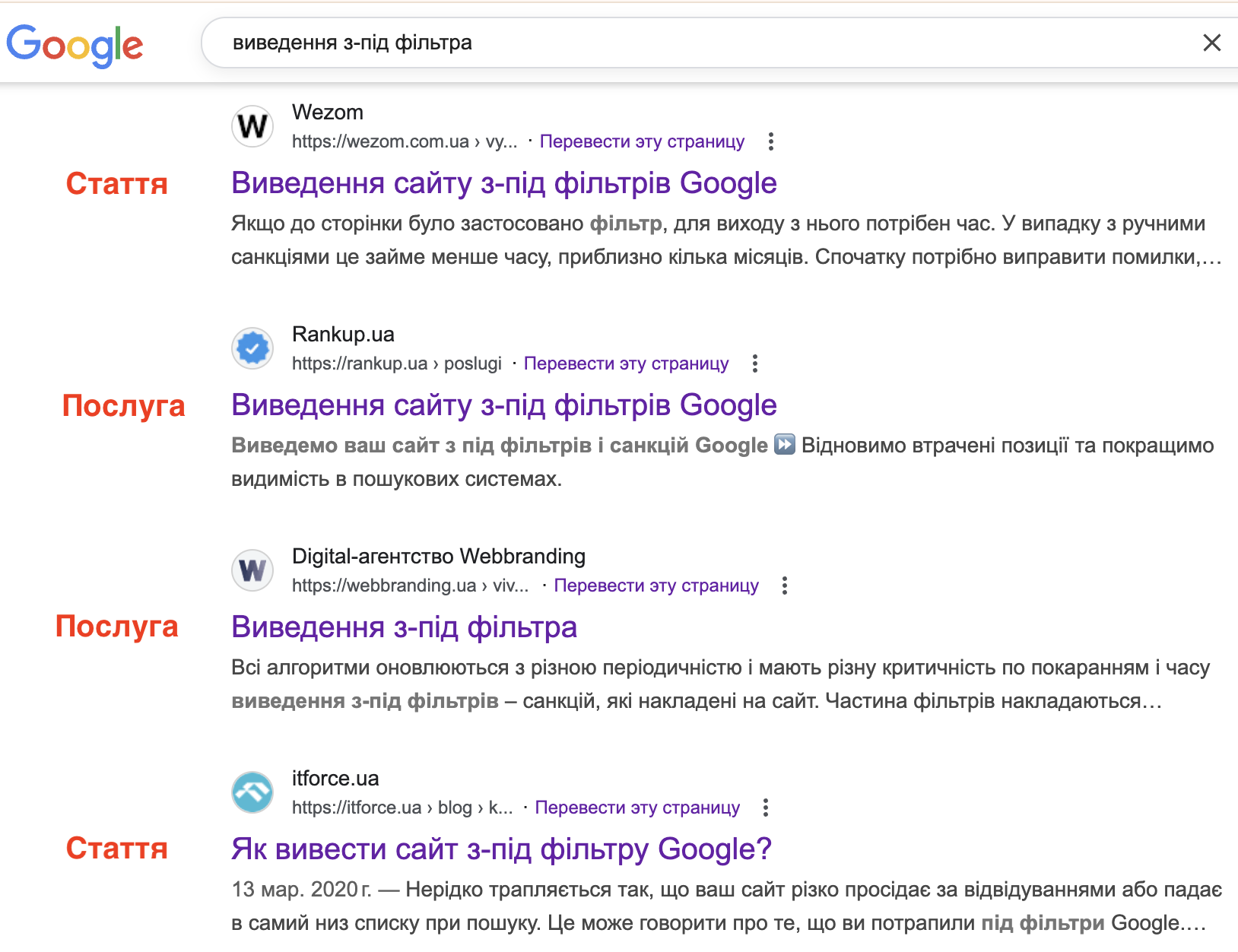
У таких випадках потрібно дивитися результати пошуку: якщо там більша частина комерції – можна включати ключ в групу з комерційними, якщо більше інформаційних – тоді в статті. Якщо 50/50 – потрібно оцінювати свій сайт, конкурентів в ТОПі та плюс окремо аналізувати ТОП 3 або ТОП 5. Наприклад, якщо 50/50, але перші 4 позиції займають комерційні проекти, тоді швидше за все і вам туди ж. Але якщо в ТОПі дуже «жирні» сайти з послугами (читай як «вкладено багато грошей в посилальне»), а нижче дрібні зі статтями, можливо є сенс боротися з останніми, це буде реальніше.
У будь-якому випадку це важливий момент. Помилки тут якраз і призводять до того, що частина запитів з ядра ранжується погано. Це викликає масу питань у клієнтів і часто призводить до припинення співпраці. А причина може бути не в поганій оптимізації, а в помилках при розподілі ключів по посадочних сторінках.
За конкуренцією
- Висококонкурентні (ВК).
- Середньоконкурентні (СК).
- Низькоконкурентні (НК).
Якщо ви новачок або ваше завдання – тільки побудова семантичного ядра, а просувати сайт буде хтось інший, сміливо пропускайте цей блок. Визначити рівень конкуренції не так вже й просто, якщо ніколи цього не робили. Так, це можна зробити за допомогою деяких інструментів, але результати малоінформативні для новачків.
Якісний аналіз робиться руками. Якщо захочете спробувати, почніть з вивчення статті про аналіз конкурентів. Потім візьміть запит, який потрібно проаналізувати, і подивіться, хто знаходиться в ТОП 10. Зробіть зведену таблицю з показниками віку, посилального, розміру, якості наповнення та оптимізації сторінок. Порівняйте зі своєю посадковою і зробіть висновок.
Такий аналіз рідко проводиться на етапі пошуку ключових слів.
За регіональністю
- Геозалежні.
- Геонезалежні.
Геозалежні – це запити, для яких пошукова система враховує місцезнаходження користувача. Наприклад, результати пошуку для «замовити піцу» в Києві та Львові будуть різними.
Геонезалежні – це запити, для яких місцезнаходження користувача не має значення. Наприклад: «як зробити скріншот», «iPhone16 відгуки».
Щоб зібрати семантику для сайту, інформація про них взагалі не обов’язкова. У більшості випадків там все очевидно. Але знати про них потрібно хоча б тому, що ви можете перебувати в одному місті, а клієнт в іншому. І результати пошуку у вас будуть різні.
Часто це призводить до ситуації, коли ключ знаходиться, скажімо, на 2 позиції, а клієнт бачить його на 7. При цьому сам він виїхав за місто і моніторить з сусідньої області. Уникнути цього легко – позиції потрібно знімати тільки в сервісах, які дозволяють все це налаштувати. Тому знати, що таке питання може надійти і як на нього відповідати потрібно.
Для чого потрібно семантичне ядро
Готове семантичне ядро, за умови, що воно правильно зібране, допоможе приблизно порахувати, скільки трафіку ви зможете отримувати, зробити правильну структуру сайту і якісно його оптимізувати.
Оцінити потенціал за трафіком
Якщо у вас зібрані всі запити, за якими буде просуватися сайт, можна спробувати оцінити, скільки трафіку на місяць він може давати. Для цього потрібно скласти частоти всіх пошукових запитів і поділити на 3. Це дуже і дуже грубий прогноз, але хоча б порядок цифр ви вже будете знати.
Наприклад, у вас в ядрі 500 ключів. Просумували частотності і отримали 30 000 показів на місяць. Якщо зможете вивести на 1-2 позицію всі пошукові запити, будете збирати відсотків 30-35 кліків від загальної кількості показів. А значить, сайт зможе збирати до 10 000 переходів на місяць або близько 330 на день. Ці цифри дуже умовні, багато що залежить від конкретної видачі – чи є там контекст, скільки його, чи є Google AI Overviews, наскільки у вас привабливі сніпети і так далі. Виходячи з практики – це цілком реальні цифри.
Якщо потенційний трафік не влаштовує і сайт ще не створений – можна прийняти рішення розширити семантику, додавши нові товари або послуги. Або взагалі відмовитися від його створення. Якщо створений і вас не влаштовував наявний трафік (за умови високих позицій), такий аналіз дозволить зрозуміти – це вже стеля по трафіку або ще є куди рости.
Сформувати структуру сайту
Якщо ви хочете отримати максимальний результат по SEO, структуру сайту потрібно робити не на підставі конкурентів і не так, як вам більше подобається. А на підставі семантики. Звичайно, конкурентів теж можна та потрібно аналізувати, але тільки не копіювати. Тому що, якщо вони допустили якісь помилки в структурі, ви теж їх скопіюєте.
Наприклад, ви підбираєте ключові слова для інтернет-магазину. У вас є ключі для 100 товарів – мікро НЧ запити по 10 показів, і для 10 розділів – СЧ і НЧ з кількістю показів від 100 до 1000. Якщо не робити структуру і всі сторінки поставити на другий рівень, для ПС вони будуть рівні за важливістю. Але який в цьому сенс? Вам же потрібно зробити більш пріоритетними розділи і направити на них більше ваги. А для цього і потрібна правильна структура.
Тому, спочатку збираєте пошукові запити, потім робите кластеризацію, а вже потім дивитеся, які групи у вас вийшли і як їх структурувати. Приклад частини такої структури для PROSUVER:
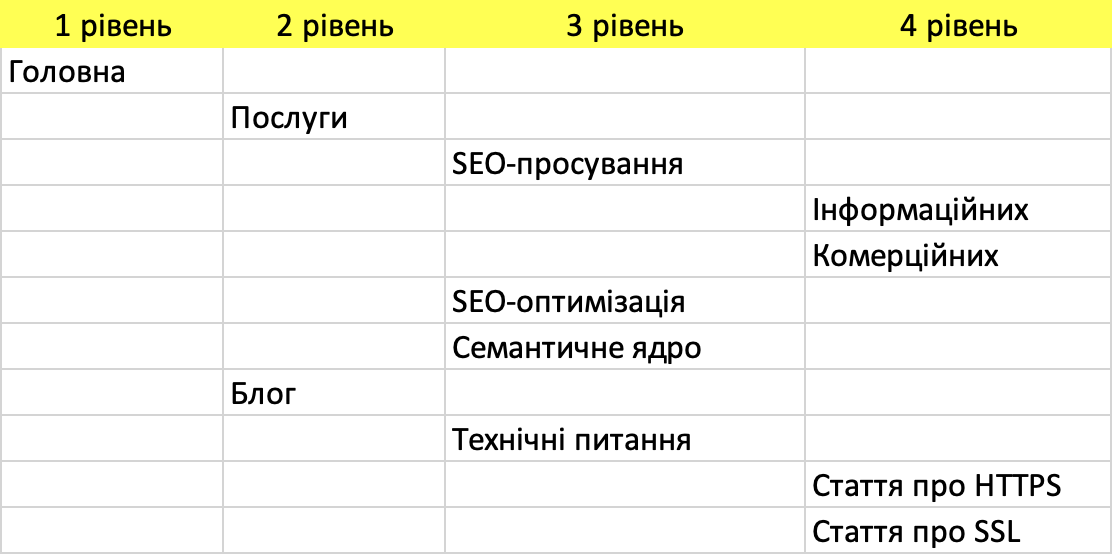
Зробити внутрішню оптимізацію
Ну і головне, для чого потрібні ключові слова – це просування сайту. Вся внутрішня оптимізація будується на семантичному ядрі:
- складання мета-тегів;
- доопрацювання заголовків h1-h6;
- аналіз та доопрацювання посадочних;
- оптимізація текстів;
- внутрішня перелінковка.
Помилки в будь-якому з цих етапів легко виправити. Але якщо неправильно зібрана семантика і ви зробили всю роботу по ній, переробляти потрібно буде практично все.
Зовнішня оптимізація також будується на семантиці, але це велика тема і про неї краще почитати в окремій статті: «Як правильно купувати посилання для просування сайту».
Як підібрати ключові слова для сайту
Складання семантичного ядра починається з підбору ключів. Спершу потрібно правильно їх зібрати, потім почистити (через стоп-слова), зняти частотності, почистити (прибрати все з 0 показів), розгрупувати, ще раз почистити (вже всередині груп) і розподілити по посадочних сторінках. Кінцевий результат – це і буде СЯ. Розберемо кожен етап.
Крок 1. Збираємо інформацію
Що потрібно знати перед підбором:
- регіон просування;
- мова;
- основні послуги або товари;
- чи буде блог (якщо мова йде про комерційні проекти);
- які сторінки найбільш важливі.
Регіон просування обов’язково потрібно уточнювати. Ситуації бувають різні. Наприклад, приходить на просування інтернет-магазин, якщо подивитися на контакти, сторінку «Про нас», буде зрозуміло, що він працює по всій країні. Але замовник хоче просуватися тільки по Києву, інші регіони його не цікавлять. У такому випадку частоту потрібно буде знімати по Києву і готове СЯ може сильно відрізнятися від варіанту під всю країну. А якщо ви зорієнтуєтеся на країну, може виявитися, що важливих запитів для Києва там немає, зате є зайві, які мають сенс тільки при роботі на країну. Ефективність просування знизиться.
Уточнювати мову потрібно тільки для багатомовних проектів. Нам часто доводиться працювати з сайтами на двох і більше мовах, власники яких замовляють просування на одній. Якщо це не уточнити, може скластися ситуація, що ви опрацюєте 2 мови і тільки на етапі узгодження СЯ дізнаєтеся, що потрібен був один. Це втрата часу, яку ніхто не буде оплачувати.
Основні товари та послуги вам знадобляться для того, щоб розуміти, що включати в ядро, а що ні. Якщо працюєте з готовим проектом, потрібно уточнити у власника – на сайті представлений повний список продукції/послуг або він готовий його розширювати, при наявності попиту. Для сайтів на етапі розробки потрібно запросити список продукції в будь-якому вигляді, але тільки не на словах, щоб потім не було «я такого не пам’ятаю», а також обговорити можливість розширення.
Чи буде блог, розділ «Статті», «Новини» або щось подібне – це вам потрібно знати, щоб розуміти, чи залишати в семантиці інформаційні запити (при опрацюванні комерційного проекту).
Які сторінки найбільш важливі? Мова про те, що продаючих сторінок може бути багато, але основний прибуток часто генерують 20-30 товарів або 3-5 послуг. Якщо їх знати, можна опрацювати їх в першу чергу, щоб швидше отримати результат.
Крок 2. Складаємо вихідний список ключових слів
Щоб правильно зібрати пошукові запити, потрібно скласти список фраз, за яким будете робити парсинг в різних сервісах. Їх називають вихідними, базовими, маркерними, якірними, стартовими, початковими. Є й інші назви, але все це одне й те саме.
Наприклад, потрібно зібрати ключі для однієї сторінки, на якій продаються автомобілі з варіатором. Вихідні запити можуть виглядати так:
Тобто, ми знаємо, що автомобіль – це ще й авто, і машина. Робимо комбінацію всіх варіантів зі словом «варіатор» і отримуємо вже якийсь список. Теоретично можна парсити по ньому. Але можна зробити його більш вузькоспрямованим або розширити.
Наприклад, якщо сайт комерційний і інформаційні запити йому не потрібні (розділу зі статтями не буде), тоді можна взяти запити вище і «обіграти» їх зі словами: купити, ціна, недорого…
Це буде більш вузькоспрямований список. По ньому спарситься набагато менше фраз та їх легше чистити, але є ризик втратити частину запитів. Наприклад, в такому варіанті після збору ви, швидше за все, не побачите «авто варіатор в Києві» – запит комерційний, але вихідні ключі не дозволять його спарсити. Щоб не пропустити такі фрази, парсинг потрібно робити за більш широким списком (без «купити» і подібного). Тим не менш, такий підхід дуже часто застосовується при посторінковому підборі ключів.
Що стосується розширення – справа в тому, що з голови дуже складно написати всі варіанти фраз, за якими потрібно робити збір, щось обов’язково забудете. Тому в нашому прикладі ми склали список найочевидніших фраз, а потім будемо розширювати його. Для цього беремо один запит зі списку та дивимося результати пошуку:
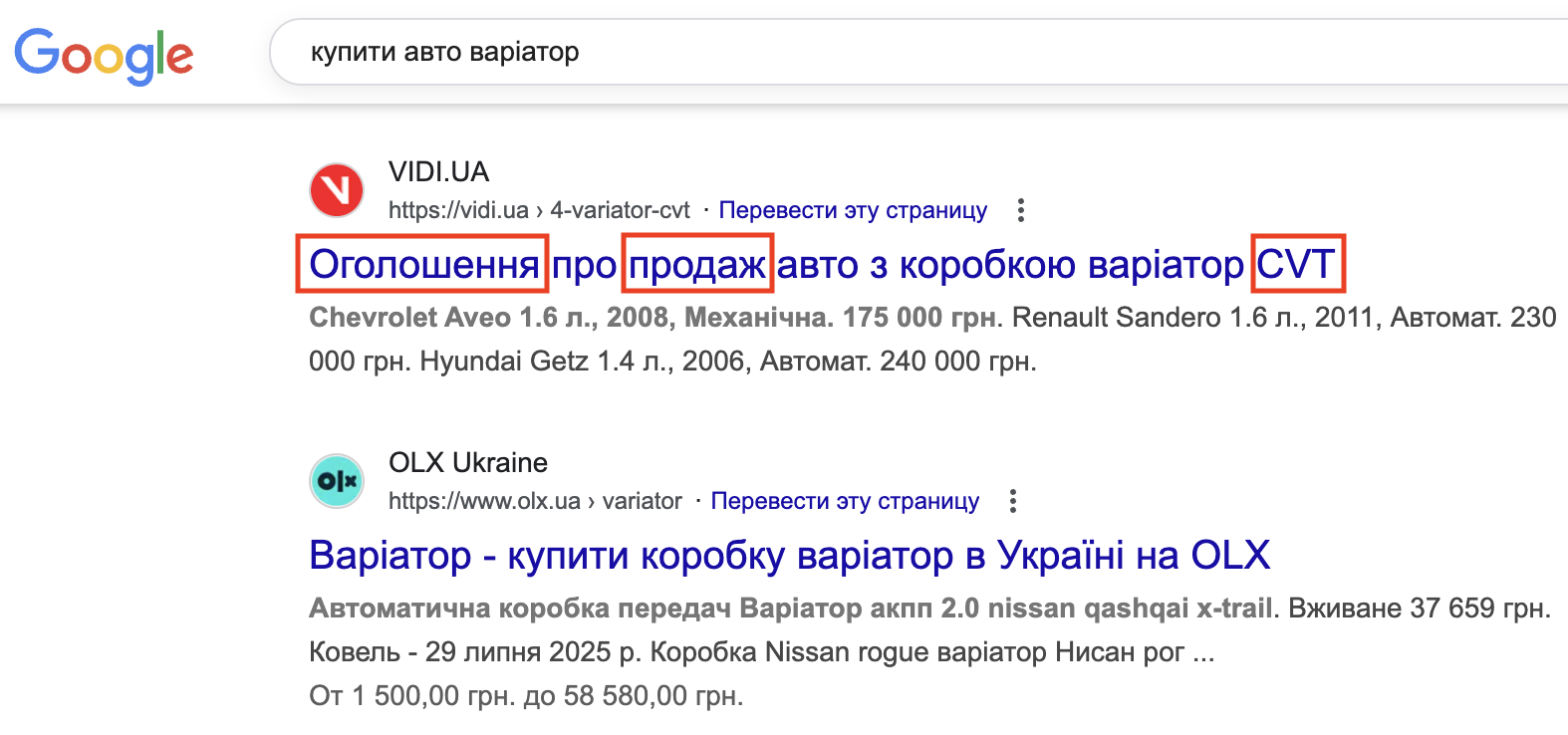
Бачимо, що замість «варіатор» можна використовувати «CVT», замість «купити» – «продаж», а якщо у вас сайт з оголошеннями, тоді і «оголошення» можна додати. І якщо спробувати розширити перший список, отримаємо:
І якщо додати до цього списку ще й варіанти зі словами «купити», «ціна», плюс розширити їх фразами зі словом «продаж», яке підгледіли у видачі, отримаємо вже досить якісний список для парсингу. Додатково можна задіяти ChatGPT – він теж може підказати якісь варіанти.
Може виникнути питання: навіщо використовувати «авто варіатор оголошення» або «авто варіатор купити», якщо подібні запити спарсяться по «авто варіатор». Теоретично так і повинно бути. Але досвід показує, що, якщо обмежитися тільки «авто варіатор», багатьох ключів зі словами «купити», «оголошення» в результатах вашого парсингу не буде. Тому список для парсингу краще робити більш докладним.
Приклад фраз, які не потрібно використовувати в нашому прикладі:
Перший ключ з неправильних занадто «широкий» для даної сторінки, за ним ви спарите не тільки варіаторні, але і взагалі будь-які авто. Запитів буде дуже багато і цим ви додасте собі роботи з очищення. Другий ключ – це НЧ, який взагалі навряд чи щось дозволить знайти – чи багато існує фраз, що містять в собі цю…
Як це робити для однієї сторінки – ми розглянули. Але ніхто не буде збирати семантичне ядро для великого сайту посторінково. Тому, перш ніж складати такі списки, потрібно подивитися на сайт та виділити якісь кластери, для яких будете робити підбір. Наприклад:
- Для малосторінкового сайту (до 50 сторінок) збір краще робити посторінково. Він буде більш якісним, ризики втратити якісь ключі мінімальні. А витрати часу не настільки і великі.
- Для вузькотематичних проектів середнього розміру можна робити збір відразу для всього сайту. Робите максимально великий список для парсингу, збираєте ключі, можливо розширюєте за рахунок конкурентів і отримуєте величезний список запитів, який потім кластеризуєте.
- Для великих і середніх проектів з великим асортиментом потрібно виділяти кластери і працювати з ними. Наприклад, середній сайт з продажу телефонів може мати кластери за брендами: iPhone, Samsung, LG і так далі. Великий інтернет-магазин з побутовою технікою: пральні машини, холодильники, пилососи і так далі.
Кількість таких кластерів залежить ще й від кількості ключових слів в цілому. Наприклад, в тій же техніці Apple їх дуже багато і там немає сенсу виділяти в один кластер всі iPhone. Запитів буде величезна кількість і розбирати їх потім незручно, набагато простіше робити підбір за моделями. Якщо ж ви робите збір по автомобілях якоїсь не дуже популярної марки, то тут вже можна збирати відразу по всій марці і потім кластеризувати, просто тому що запитів набагато менше.
Опрацювання в такому випадку буде поетапним. Взяли один розділ – опрацювали, взяли другий – опрацювали, і так весь сайт. Є тільки один мінус – якщо проект занадто великий, це може зайняти багато часу. У такому випадку вам і знадобляться найбільш важливі сторінки/товари/розділи. Уточнили у клієнта, що для нього є пріоритетним – опрацювали та поставили збір СЯ на паузу. Оптимізуєте дані сторінки і потім продовжуєте збір. А в цей час Google вже почне індексувати зміни і може з’явитися перша динаміка по позиціях.
Якщо коротко:
- Переглядаєте сайт та розбиваєте його на кластери.
- Вибираєте один і складаєте для нього фрази, за якими будете робити парсинг.
- Розширюєте цей список за рахунок результатів пошуку Google, ChatGPT, сервісів для підбору запитів, конкурентів.
- Опрацьовуєте та починаєте наступний кластер.
Крок 3. Парсинг
Тепер потрібно зробити парсинг ключових слів за тими списками, які ви склали. Джерел та сервісів для парсингу багато, але вони не використовуються одночасно всі. Ви ж не будете оплачувати 5 сервісів для збору семантичного ядра, якщо вони багато в чому дублюють один одного. Підбирати їх потрібно під конкретне завдання і ваш бюджет. У цій статті наведу кілька варіантів, яких буде достатньо для збору СЯ більшості сайтів при просуванні в Google.
Джерела ключових слів
- Пошукові запити.
- Пошукові підказки.
- Конкуренти.
Пошукові запити – це те, що користувачі вбивають у пошуковий рядок браузера. Їх збирає, підраховує частотності та зберігає пошукова система. У нашому випадку, Google. Це перше, що нас цікавить.
Пошукові підказки – це те, що пропонує пошукова система, коли ви вводите запит у пошуковий рядок:
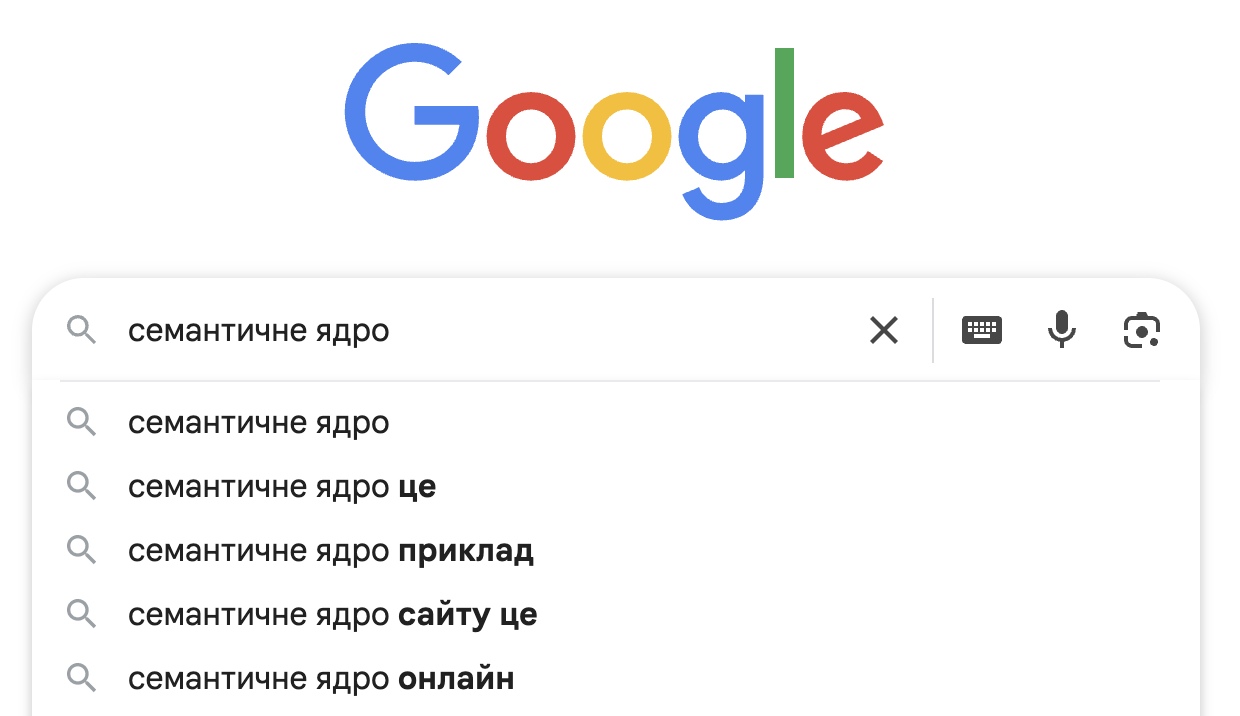
Семантичне ядро конкурентів – це перелік запитів, під яким вони просуваються. Саме його ми дізнатися не можемо. Але можемо дізнатися запити, за якими користувачі знаходили у пошуку їхні сайти та переходили на них. Іноді аналіз конкурентів може дати багато ключів, які не вийде одержати з перших двох джерел.
Які послуги використовувати
Якщо джерел потрібно якнайбільше, щоб СЯ було повнішим, то сервісів якнайменше, щоб зменшити витрати на софт. Тому я покажу дуже невеликий набір із того, чим користуюся сам. Це не означає, що це рішення єдине правильне, але воно дозволить зібрати семантику на дуже високому рівні без великих витрат.
Які послуги для пошуку ключових слів можна використовувати:
- Google Keyword Planner;
- Google Search Console та Google Analytics;
- Serpstat;
- Ahrefs;
- Keyword Tool;
- SemRush;
- SE Ranking.
Це далеко не повний перелік. Але навіть з нього ми будемо використовувати лише перші 4. Та й те, Ahrefs можна було б виключити, але він потрібен для аналізу посилань, тому є у більшості SEO-шників. А якщо так, який сенс його ігнорувати. На етапі збору зайвих ключів не буває.
Google Keyword Planner (це Планувальник ключових слів у Google Ads) використовується практично завжди. Він показує саме ті запити, які користувачі вбивають у пошуковий рядок Google та частотності за ними. Він безкоштовний і не потребує додаткових програм та сервісів. Щоб працювати з ним, потрібно створити обліковий запис в ads.google.com, створити першу рекламну компанію (не оплачуючи), потім відкрити сам Планувальник:
https://ads.google.com/aw/keywordplanner/home
Google Search Console та Google Analytics використовуються, коли у вас є до них доступ і сайт має якийсь трафік. Не підходить для проектів без трафіку або при зборі семантичного ядра на етапі розробки. Якщо проект ваш – додаєте його в Search Console, підключаєте Аналітику, чекаєте, поки оновляться дані і можна буде використовувати. Якщо клієнтський – просите власника делегувати права та працюєте. Посилання не даю, вони легко гугляться, там складно помилитися.
Serpstat та Ahrefs – це платні сервіси, які допоможуть дізнатися ключові слова конкурентів. Насправді можливостей у них набагато більше. Але я намагаюся показати мінімальний набір дій, щоб не перевантажувати статтю, але і не знижувати якість майбутнього СЯ. Якщо вам потрібен тільки збір семантики для сайту, і ви не збираєтеся його просувати – тоді Serpstat буде достатньо. Якщо ви SEO-шник, та ще й не новачок, Ahrefs у вас швидше за все вже є, в такому випадку використовуйте і його теж.
Який підхід вибрати в залежності від сайту
Які сервіси використовувати і який підхід вибрати залежить від сайту і мети. Перерахую те, з чим будете стикатися найчастіше.
Новий сайт (на етапі розробки або тільки створений):
- Парсите: пошукові запити, підказки та конкурентів.
- Знадобиться: Планувальник, Serpstat.
- Спосіб збору: робите одну велику групу, яку потім будете розгруповувати.
Робочий сайт зі сформованою структурою та трафіком:
- Парсите: пошукові запити, підказки та статистику. Конкурентів додаємо тільки при необхідності.
- Знадобляться: Планувальник, Google Search Console, Google Analytics, Serpstat.
- Спосіб збору: збираєте посторінково (для дрібних сайтів) або по розділах (для середніх).
Великий сайт з великим трафіком:
- Парсите: статистику.
- Знадобляться: Google Search Console, Google Analytics.
- Спосіб збору: збираєте всю статистику в один великий список, видаляєте запити з частотою менше 50 показів (цифра варіюється в залежності від проекту), і ті, які знаходяться на 1-2 позиції або далі 20-30. Решту розподіляєте по посадочних та просуваєте.
Останній підхід дозволяє збільшити трафік великого проекту в мінімальні терміни. Якщо почнете з повного ядра, до просування можете дістатися і через півроку. А це зазвичай неприпустимо. І тільки після того, як результат буде досягнутий, можна збирати всю семантику, та й то блоками. Наприклад, зібрали «побутову техніку» з усіма вкладеними пральними машинами, мікрохвильовками та іншим, опрацювали внутрішню оптимізацію розділу і тільки після цього берете наступний.
Приклад парсингу
Давайте подивимося, як процес збору виглядає на практиці. Я розписую на прикладі однієї сторінки/розділу для 1 групи вихідних ключових слів. Якщо у вас їх багато, повторюйте для кожної окремо і результати заносьте в Excel (1 група – 1 стовпець).
Припустимо, мій список для парсингу виглядає так:
семантичне ядро
ключове слово
пошуковий запит
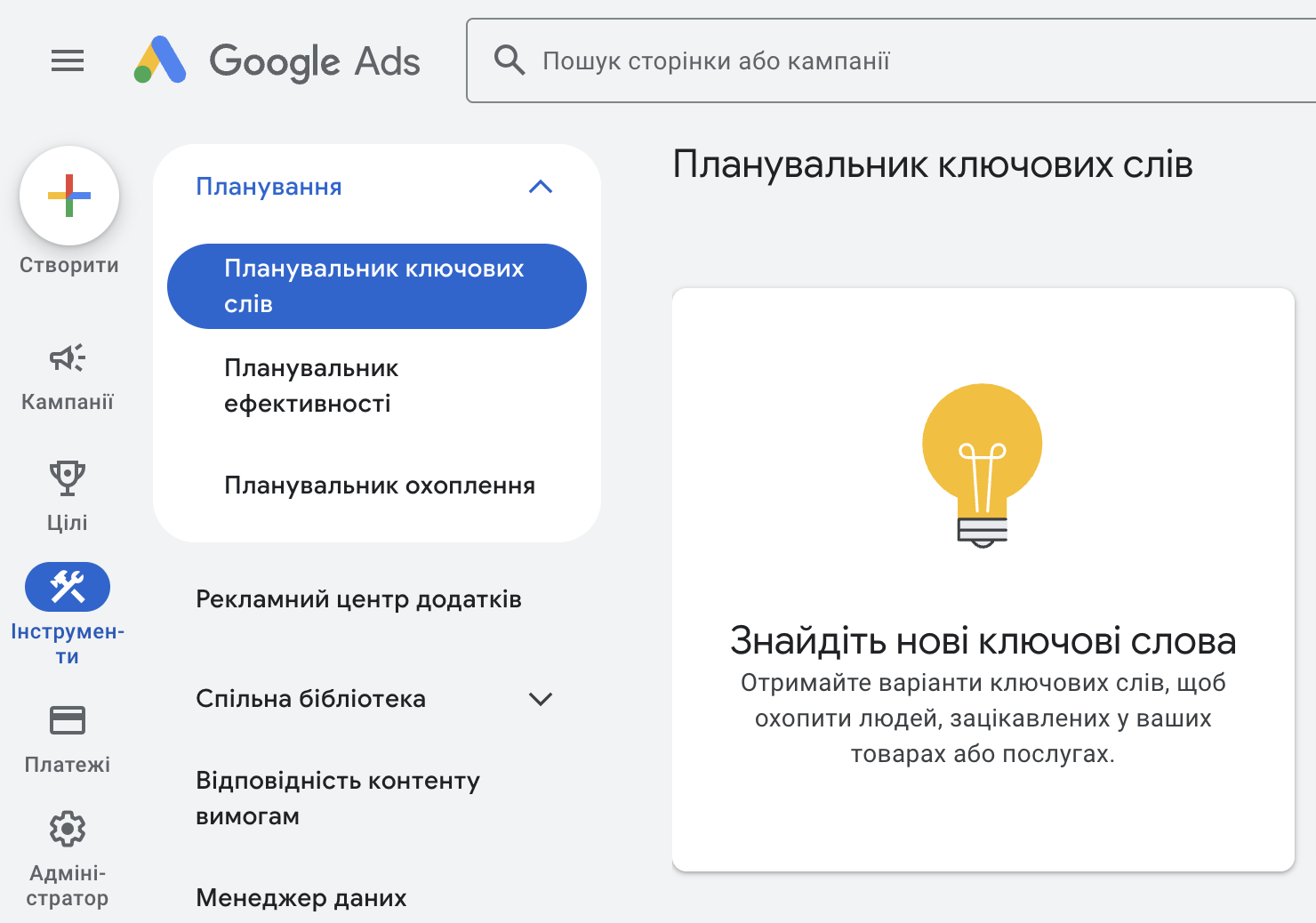
Відкриваємо Excel і переносимо цей список у стовпець «А». Відкриваємо Google Keyword Planner, натискаємо «Знайти нові ключові слова»:
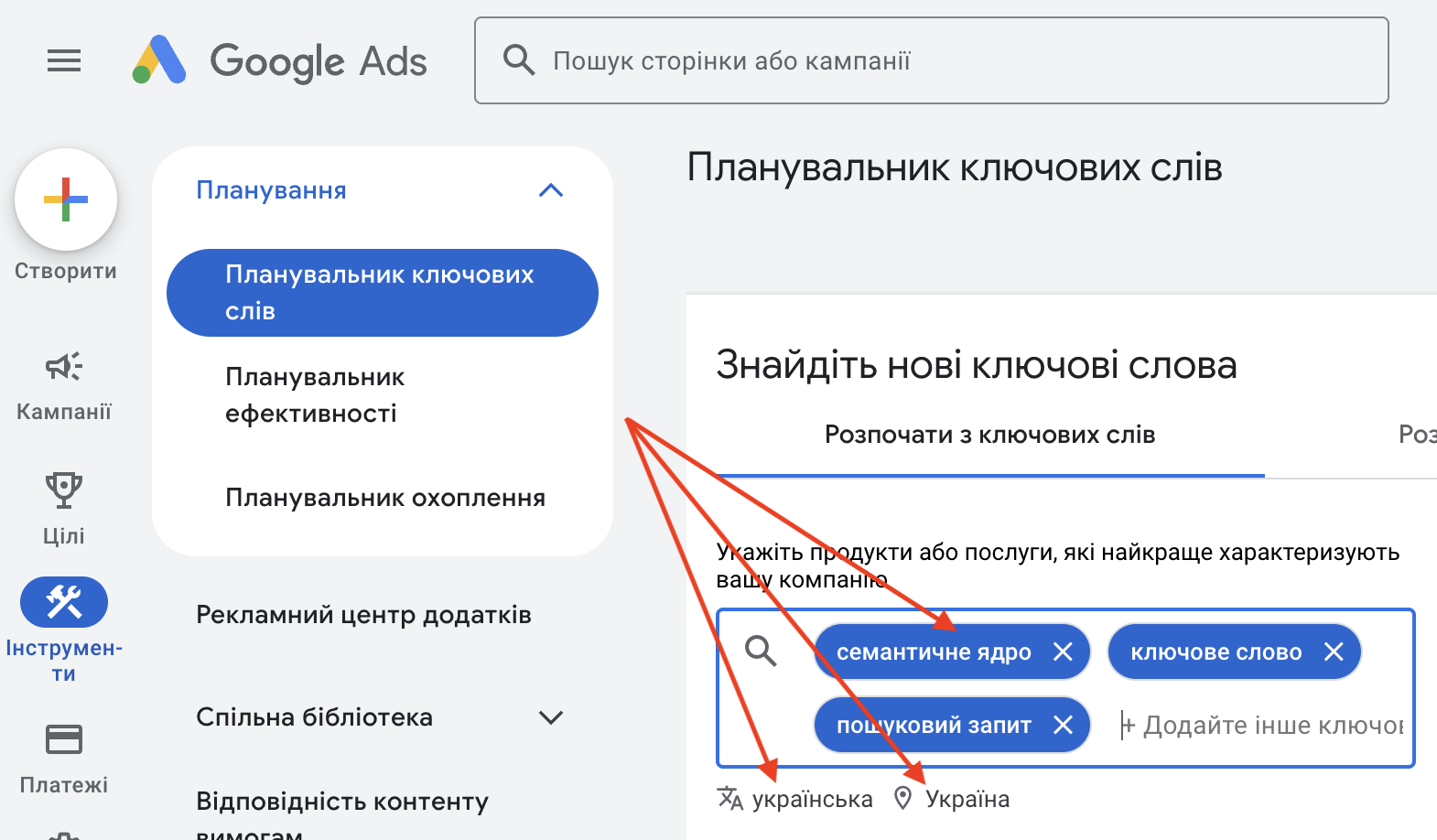
Вставляємо список для парсингу, вибираємо регіон, для якого робимо збір, та мову:
Натискаємо «Переглянути результати» і в наступному вікні завантажуємо результати підбору, натиснувши сюди:
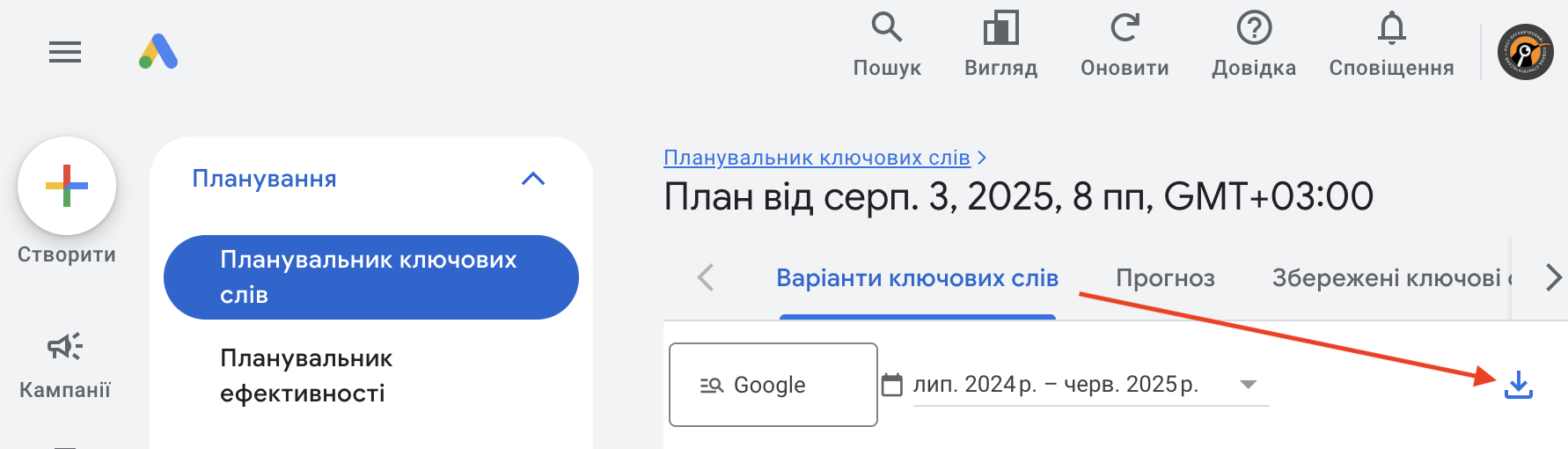
Відкриваємо отриманий файл, копіюємо тільки список ключових слів з першого стовпця та вставляємо їх у стовпець «А» того документа Excel, який створили вище, назвемо його «робочий». Планувальник можна закривати.
Тепер зберемо пошукові підказки через Serpstat. Авторизуємося, відкриваємо «Аналіз ключових слів – Пошукові підказки», вибираємо країну, вводимо перший запит з нашого списку вихідних:
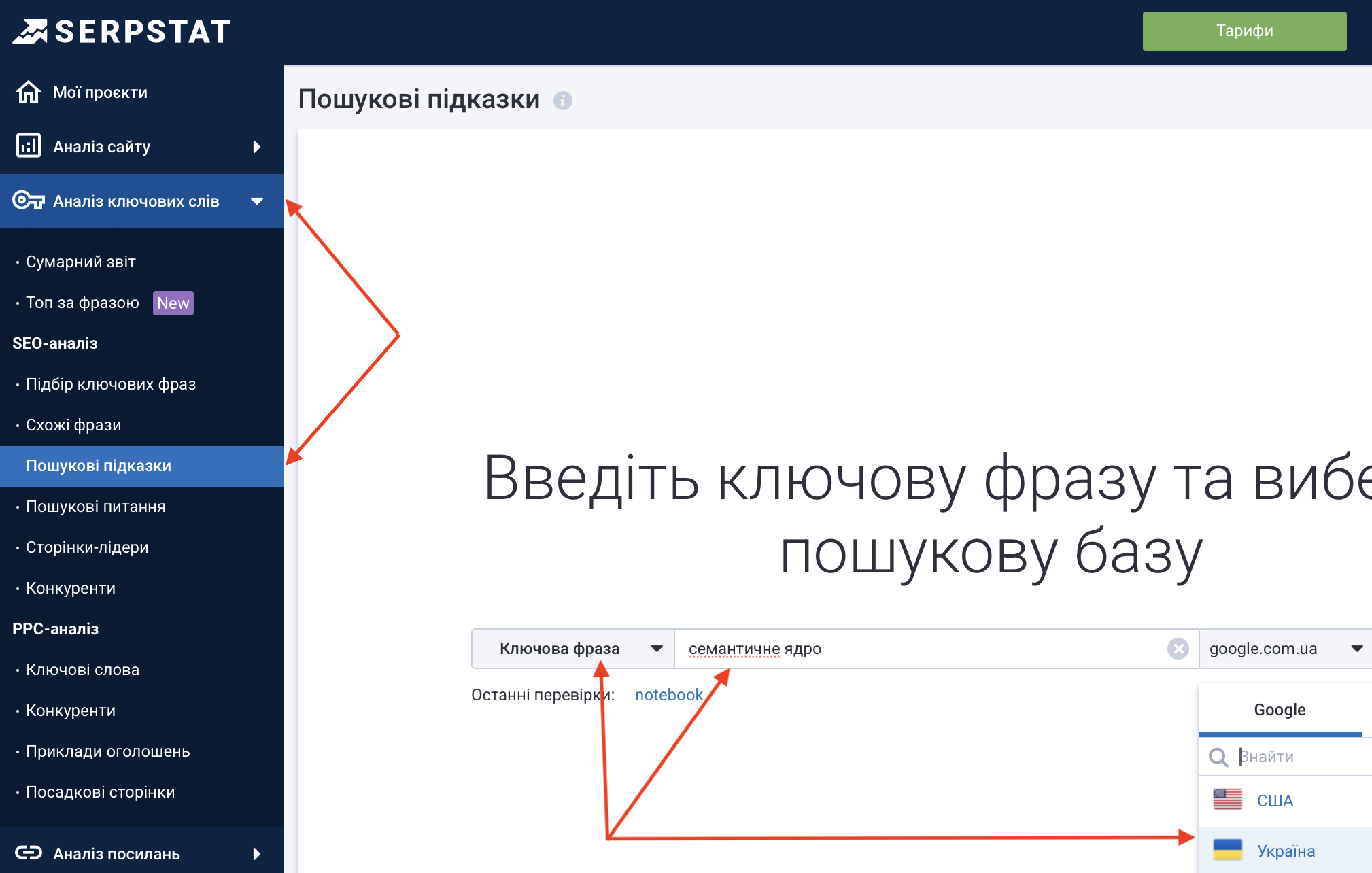
Натискаємо «Знайти», відкривається сторінка з результатами підбору. У правому верхньому куті натискаємо на «Експорт» і завантажуємо файл в будь-якому зручному форматі. Відкриваємо файл та також копіюємо з нього всі підказки в стовпець «А» робочого Excel. Потім повторюємо всі кроки для двох фраз, що залишилися з вихідного списку.
Зверніть увагу, в бічному меню є ще й «Пошукові питання» – це також корисний інструмент, але потрібний не всім і не завжди. Якщо робите посторінковий підбір і на сторінці, що просувається доречно використовувати блок з питаннями – додавайте і їх.
Залишилося подивитися ключові слова конкурентів. Це можна зробити і в Serpstat, але для різноманітності скористаємося Ahrefs. Є 2 варіанти:
- Авторизуватися в Ahrefs, відкрити «Keywords Explorer», вписати першу вихідну фразу і в результатах, що відкрилися, подивитися ТОП 10 сторінок за даною фразою та переходячи за посиланнями подивитися ключі, за якими вони ранжуються.
- Самостійно вивчити результати пошуку в Google, вибрати кращі сторінки і перевіряти вже те, що найбільше сподобалося.
Простіше перший, краще другий. Чому так? Результати пошуку за різними фразами з вихідного списку можуть відрізнятися, а значить, щоб отримати більш повну картину доведеться перевіряти їх всі, вибираючи неповторні сайти. Плюс у змішаній видачі половина сторінок взагалі повинна бути відкинута, а тих, що залишилися, може не вистачити. Тому краще взяти 1 запит і подивитися по ньому ТОП 20-30, відкрити кожну сторінку, оцінити, наскільки вона збігається з тим, що вам потрібно, та відібрати для аналізу кілька дійсно підходящих.
Наприклад, ви збираєтеся писати статтю «Як правильно скласти семантичне ядро». Починаєте аналізувати результати пошуку і бачите, що частина з них – це сторінки якихось сервісів, ще частина – це послуги. Навіщо вам збирати їх ключі? У такому випадку вам потрібно вибрати кілька якісних статей і аналізувати їх.
Коли список url-адрес буде готовий, авторизуєтеся в Ahrefs, відкриваєте «Site Explorer», вводите перший url та вибираєте «Exact URL»:
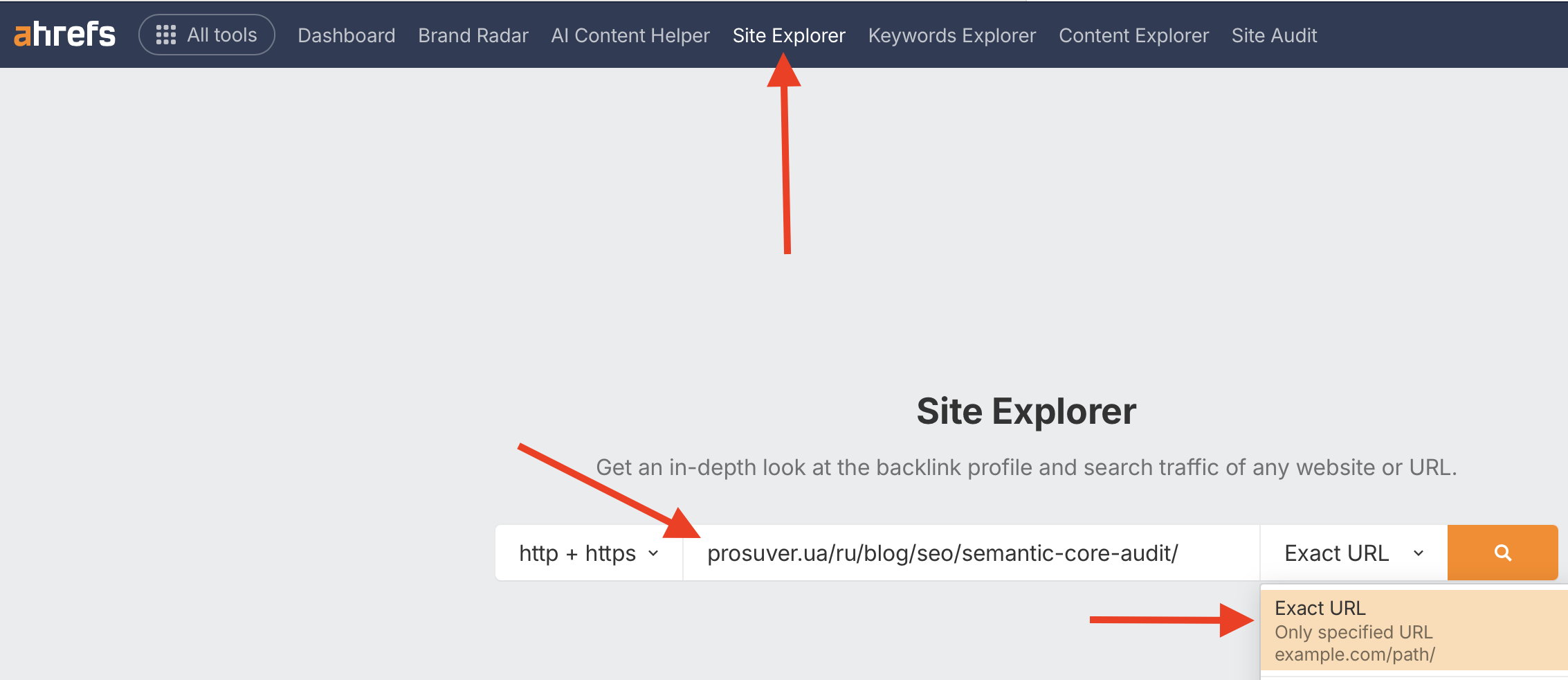
Натискаєте на помаранчеву кнопку з лупою і у вікні, що відкрилося, в бічному меню вибираєте «Organic keywords»:
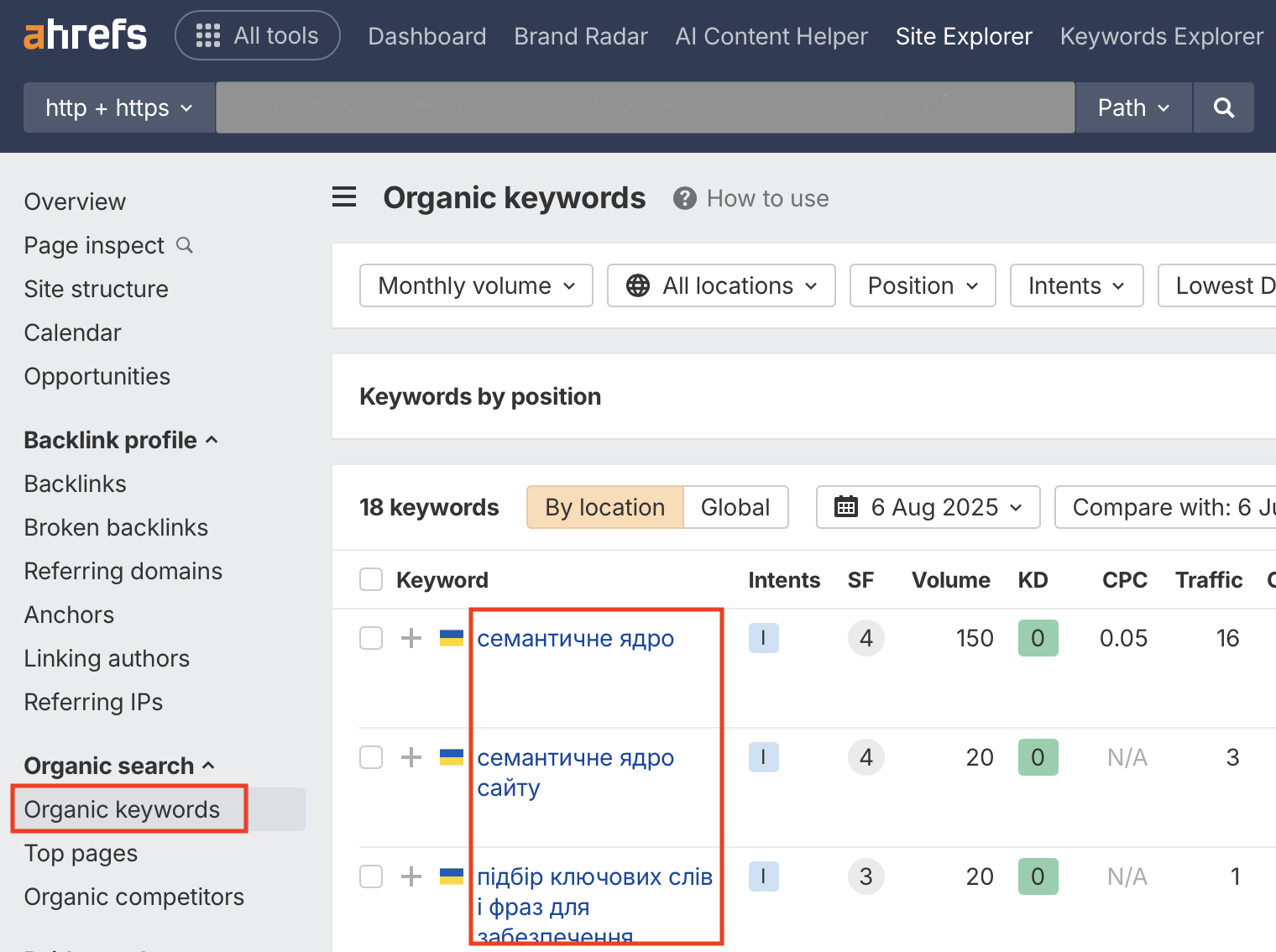
Це і будуть ключові слова конкурента. Завантажуєте через кнопку «Export» у правому верхньому кутку, переносите їх у робочий Excel і робите те саме з усіма відібраними сторінками.
Найчастіше на цьому збір зупиняємо. Але якщо вам потрібно зібрати ключові слова для сайту (а не сторінки/розділу) і є можливість завантажити дані з Google Аналітики або Search Console, тоді відкриваєте їх та завантажуєте ще й звідти. Хоча для нашого прикладу в цьому мало сенсу, тому що зараз розбираємо одну групу, а з цих сервісів ви завантажуєте пошукові запити відразу для всього сайту.
Тож докладно розбирати не будемо, там нічого складного. Наприклад, у Google Search Console потрібно просто відкрити розділ «Ефективність» та експортувати всі ключі:
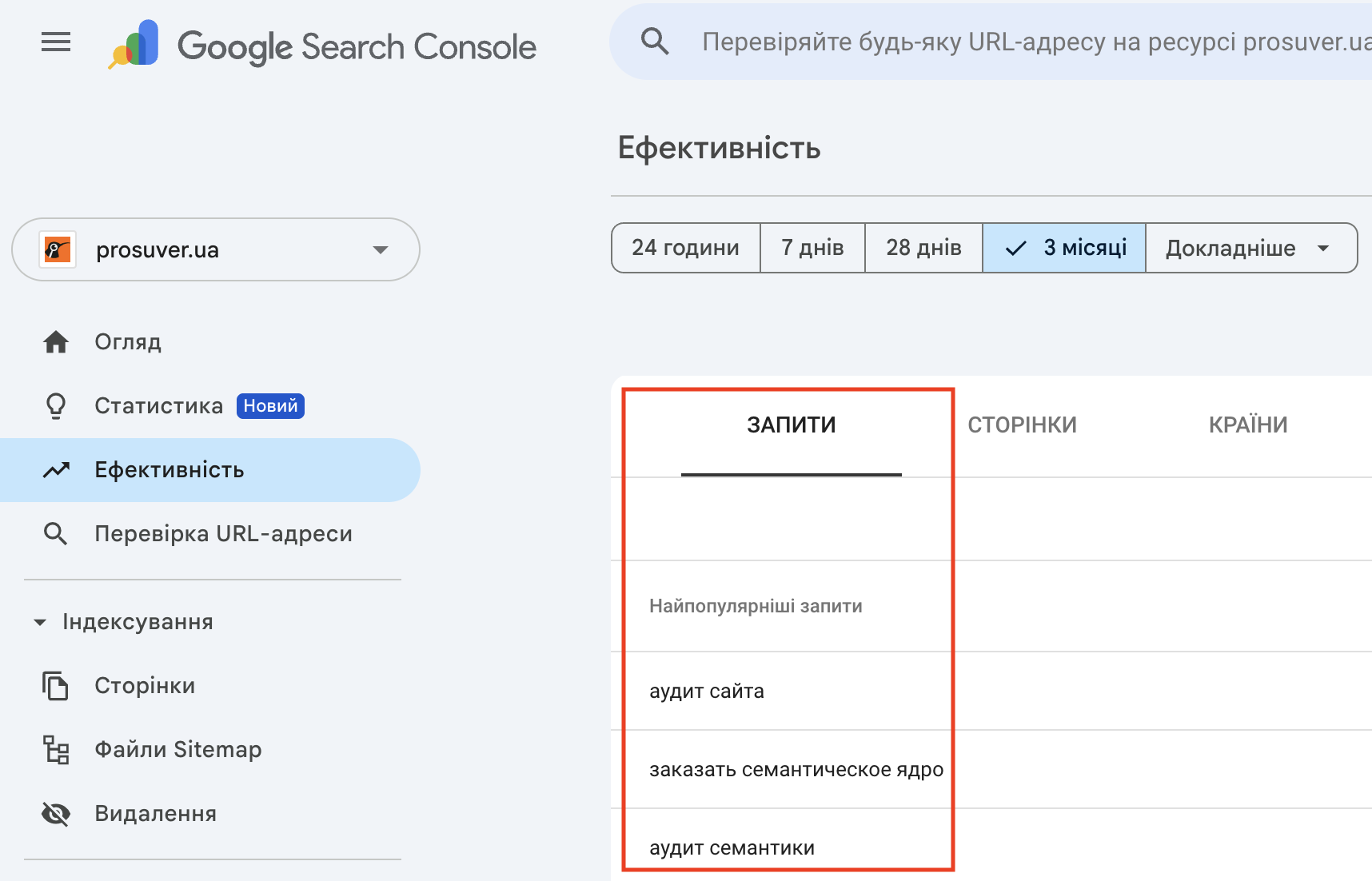
З Google Аналітикою працювати трохи складніше і якщо у вас немає досвіду роботи з нею, пропускайте. Того, що зібрано вже достатньо.
Після всіх кроків у Excel буде один стовпець з великою кількістю фраз. Причому кількість може змінюватись від десятків до десятків тисяч. Тож нехай вас не лякає кількість рядків. На цьому підбір ключових слів закінчено. Принаймні для однієї групи чи сторінки. Тепер повторюєте його для інших груп або сторінок (заповнюєте стовпи B, C… в Excel) та переходьте до наступного етапу. А якщо збір робили для сайту відразу, тоді повторювати нічого не потрібно.
Крок 4. Чищення
Найкращий спосіб чищення ключових слів – прочитати всі фрази, які ви відібрали, та видалити зайві. Наприклад, у вас сторінка із продажу кухонних столів. Ви ж розумієте, що “купити стіл для кухні” – це відповідний ключ, а “як зробити кухонний стіл своїми руками” – ні. Подумати змушують лише варіанти виду «кухонний стіл», де незрозуміло, що користувач шукає товар чи інформацію. Але це ми вже розібрали вище – робите аналіз результатів пошуку та приймаєте рішення.
Якщо після парсингу у вашому списку в Excel хоча б до 1000 рядків, можете сміливо йти цим шляхом. Вони вичитуються досить швидко і ризики втратити щось важливе майже відсутні.
Якщо мова про тисячі чи десятки тисяч – чищення семантичного ядра робиться як мінімум у 2 етапи: попередня (груба) та остаточна (фінальна). Фінальну краще робити разом із кластеризацією. А зараз розберемо, як очистити пошукові запити від зовсім невідповідних слів та різного сміття.
Стоп-слова
Якщо скласти хороший список стоп-слів, можна в кілька кліків скоротити десятитисячний список напарсених ключів до 2-3 тис. Щоб скласти такий список, потрібно відкрити робочий Excel і поруч будь-який текстовий редактор. Далі починаєте вичитувати спарсенні запити і, якщо вони містять якісь слова, які точно роблять їх невідповідними для вас – переносите ці слова в текстовий редактор.
Наприклад, у нас стаття «Як збирати семантичне ядро», для якої ми і робили збір. Якщо при чищенні бачимо: «замовити СЯ» – копіюємо слово «замовити» в текстовий редактор, тому що будь-які фрази, які його містять, нам не підійдуть, вони комерційні. Або «як зібрати семантику для контексту» – копіюємо слово «контексту», тому що там потрібен трохи інший підхід і немає сенсу описувати його в одній статті з підбором під SEO. Або з «аналіз пошукових запитів ютуб» беремо «ютуб». І так далі.
Список стоп-слів буде виглядати так:
купити
замовити
ціна
вартість
недорого
дешево
ютуб
контекст
…
Основне питання – скільки вичитувати? Якщо у вас в робочому Excel тисяч 10-20 рядків, не потрібно читати їх всі. Прочитайте або перші кілька сотень, або просто прокрутіть документ довільно і виписуйте те, що впало в око. Наприклад, прокрутили довільно кілька десятків рядків, виписали те, що побачили, ще кілька десятків або сотню – виписали і так далі.
Але якщо ви робите підбір для великого проекту з великою кількістю однотипних сторінок і великою кількістю ключів, є сенс заморочитися і постаратися витягнути максимальний список стоп-слів з першої групи. Нехай ви витратите на це багато часу, зате потім заощадите його дуже багато на інших сторінках. У такому випадку вичитати краще відразу кілька тисяч рядків або навіть всі фрази з першої групи.
Коли список готовий, потрібно скористатися якимось софтом, сервісом або скриптом, які дозволять завантажити список ключових слів, список стоп-слів і, натиснувши на одну-дві кнопки, отримати список запитів без стоп-слів. Варіантів, як це зробити, багато, але в основному вони платні. У даній статті я їх не буду зачіпати, щоб і не розтягувати, і не переплачувати. Покажу максимально простий і безкоштовний варіант:
- відкриваєте Google Таблиці;
- створюєте 3 вкладки: Keywords, Stop words, List after cleaning (назви на ваш розсуд);
- в меню Google Таблиць відкриваєте «Розширення – Apps Script» і додаєте код:
function cleanList() {
var ss = SpreadsheetApp.getActiveSpreadsheet();
var keywordsSheet = ss.getSheetByName("Keywords");
var stopWordsSheet = ss.getSheetByName("Stop words");
var cleanedSheet = ss.getSheetByName("List after cleaning");
// Отримуємо дані
var keywordsData = keywordsSheet.getRange(1, 1, keywordsSheet.getLastRow(), 1).getValues().map(r => r[0]);
var stopWordsData = stopWordsSheet.getRange(1, 1, stopWordsSheet.getLastRow(), 1).getValues().map(r => r[0].toLowerCase());
// Фільтрація
var result = keywordsData.filter(q => {
var lowerQ = (q + "").toLowerCase();
return !stopWordsData.some(stop => lowerQ.includes(stop));
});
// Виведення результату
cleanedSheet.clear();
cleanedSheet.getRange(1, 1, result.length, 1).setValues(result.map(r => [r]));
}- зберігаєте та повертаєтеся в Google Таблиці;
- на вкладці «Keywords» робите «Вставка – Малюнок – Фігура», додаєте прямокутник або будь-яку фігуру, і підписуєте «Clean list» або як вам подобається – це просто кнопка, яку будете натискати, щоб отримати результат;
- натискаєте на створеній кнопці правою кнопкою миші, вибираєте «Призначити скрипт» та вписуєте:
cleanList
На цьому все. Вставляєте список пошукових запитів з робочого Excel на вкладку «Keywords», стоп-слова на вкладку «Stop words», натискаєте на кнопку «Clean list» і на вкладці «List after cleaning» отримуєте вже очищений список запитів. Переносите його в робочий Excel, на окрему вкладку (раптом десь помилилися, щоб потім не робити парсинг повторно).
Частотності
Оскільки кількість фраз значно скоротилася, тепер можна зняти частотності з тих, що залишилися, і видалити ті, які мають 0 показів на місяць. Це може скоротити ваш список ще в 2-3 рази та більше. Можна було б і раніше зняти частотність, але тоді довелося б сильно переплатити.
Тут також є зручні платні рішення. Але поки що розглянемо безкоштовний варіант. Відкриваєте Планувальник ключових слів, але вибираєте не «Знайдіть нові ключові слова», а «Отримайте дані про кількість пошуків і прогнози»:
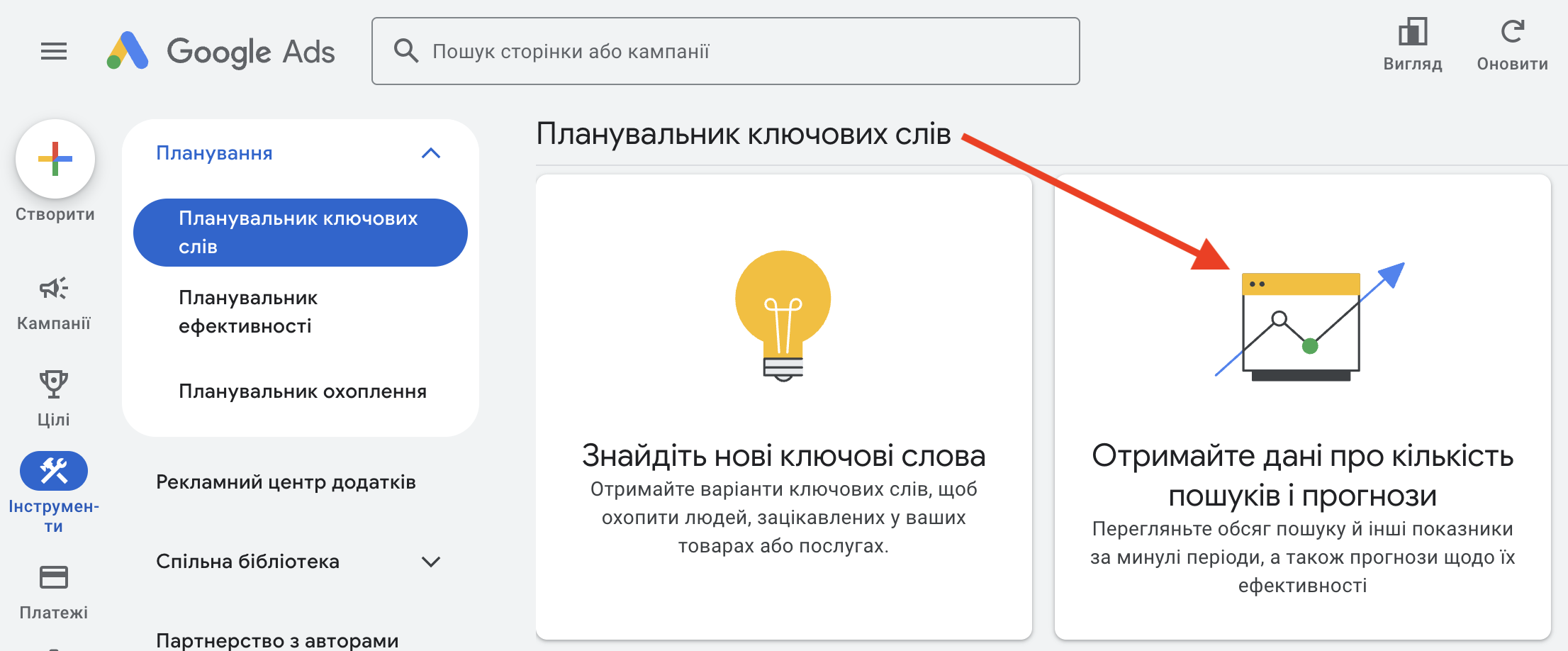
Далі все аналогічно підбору – вставляєте очищені стоп-словами запити, натискаєте «Почати», вказуєте країну і мову. Експортуєте отримані результати.
Відкриваєте експортований файл в Excel, потім «Дані – Сортування» та налаштовуєте сортування в порядку убування частотності. Видаляєте всі рядки з 0 показів. Решту ключів з частотами переносите в робочий Excel.
На цьому попереднє очищення закінчено.
Крок 5. Кластеризація
Кластеризація ключових слів вимагає різних підходів для різних вихідних даних. Я покажу кілька поширених моментів.
Якщо сайт добре ранжується
Якщо ви опрацьовуєте сайт з хорошими позиціями – тоді потрібно зняти позиції і в робочий Excel додати стовпці з позиціями та сторінками, які ранжуються за цими ключами. Потім зробити сортування ключових слів (через фільтр) по стовпцю «Сторінка» від А до Я. В результаті має вийти ось так:

Потім розділяєте групи з однаковими url-адресами парою порожніх рядків та отримуєте готові групи ключів і відразу посадочні сторінки для них. Якщо запиту немає в ТОП 100 і позиція по ньому не знялася – прибираєте його або за змістом переносите в відповідну групу.
І ось тут вже потрібна буде фінальна чистка. Кожну групу потрібно буде уважно вичитати та видалити все, що не підходить.
Залежно від мети та поточних позицій сайту з таким ядром можна працювати дуже гнучко. Наприклад, залишити тільки ті фрази, які вже знаходяться в ТОП 5-20 і працювати з ними. Що дасть максимально швидкий результат по трафіку. Або, навпаки, максимально розширити семантику, щоб вибудувати стратегію просування на тривалий період.
Якщо сайт не ранжується
Тут вже не принципово – сайт на етапі розробки або новий/старий без трафіку. Якщо кластеризація пошукових запитів по релевантній сторінці неможлива, значить сортування потрібно робити за змістом.
Наприклад, у вас проект з продажу квітів. Можна зробити групування запитів за їх видами. Вибрали все, де є згадка про троянди в одну велику підгрупу і працюєте з нею. Робите фінальне очищення і потім розподіляєте фрази за змістом:
купити троянди
магазин купити троянди
купити троянди ціна
купити червоні троянди
квіти троянди червоні купити
сині троянди купити
сині троянди купити доставка
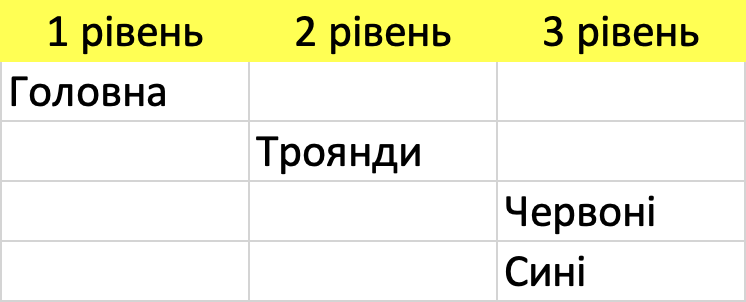
Паралельно з цим заведіть в робочому Excel ще один аркуш, назвіть його «Структура» та починайте формувати майбутню структуру сайту (якщо вона ще не зроблена):
Таке групування семантичного ядра займає дійсно багато часу і деякі намагаються автоматизувати процес, використовуючи різні сервіси. Такий підхід іноді можна застосовувати, але тільки не в тому випадку, коли у вас майже немає досвіду. І не в тому випадку, коли вам потрібно дійсно правильне семантичне ядро, з яким можна вибудовувати довгострокову стратегію. Якщо коротко: потрібна висока якість – робіть руками.
На що звернути увагу
1. Релевантність ключових слів
Потрібно переконатися, що запити, які ви відбираєте, релевантні сторінці. Наприклад, ті ж троянди. Якщо ви працюєте з інтернет-магазином з продажу букетів, то запит «купити троянди» вам може і не підійти. Тому що більша частина сайтів в ТОП 10 може продавати саджанці, а у вас букети. Відповідно такий ключ вимагає аналізу або видалення з СЯ.
2. Чи не потрібно розділити групу
Іноді в одну групу можуть потрапити запити, за якими потрібно просувати різні сторінки. Наприклад:
купити позашляховик
купити позашляховик дизельний
купити позашляховик б/у
Якщо подивитися результати пошуку за першими двома – вони абсолютно різні. І якщо ви хочете високі позиції за обома ключами – потрібно робити окремі посадочні. Третій запит також має свою видачу, більше заточену на дошки оголошень та онлайн-авторинки. У той час як за першим можуть більше ранжуватися салони або видача буде змішаною, що теж вимагатиме аналізу. Тобто, вони можуть і схожі, але сторінки будуть різні. А навіть якщо десь і однакові, то в таких спірних моментах ви повинні обов’язково в цьому переконатися, зробивши відповідний аналіз.
3. Синоніми повинні бути об’єднані на одній сторінці
Мова про те, що немає сенсу писати 2 окремі статті типу: «Як підібрати семантичне ядро» та «Як підібрати ключові слова». Так, можна під кожну зібрати свою семантику, зробити різну структуру статей, по-різному їх написати, оформити. Але це одне і те ж. І якщо 10 років тому Google міг дати трафік на обидві, то зараз при великій кількості подібних смислових дублів ви швидше отримаєте зниження позицій.
Поширені запитання
- Скільки запитів потрібно включити в СЯ?
Кількість груп в СЯ не обмежена. Аби ви могли це обробити. Тому що, якщо зібрати 10 000 ключів і потім кілька років опрацьовувати під них сторінки – це буде не найкраща ідея…
- Що робити з ключовими словами з помилками?
Якщо по них високі частоти – обов’язково залишаємо в ядрі і відстежуємо по них позиції. Є попит – це потрібно використовувати. Але при оптимізації сторінок застосовуємо тільки слова без помилок та правильні мовні звороти.
- Що робити з фразами, у яких різний порядок слів?
Мова про «купити холодильник недорого» та «купити недорого холодильник». Для Google це можуть бути різні фрази з різною кількістю показів. Тому тут потрібно орієнтуватися на те, для чого вам семантика. Якщо ви робите її на етапі розробки проекту, та СЯ вам потрібно, щоб оцінити потенційний трафік і обсяг ніші, тоді залишаєте обидва варіанти. Якщо це звичайне ядро для просування, такі дублі тільки зайве місце займають, тому що позиція буде або однакова, або відрізнятися незначно. Можна видалити.
- Чи можна використовувати підхід «1 ключ – 1 сторінка»?
Ні. Виняток – сайти в мікронішах, де більшої кількості просто немає. Але це рідкість. У всіх інших випадках для кожної посадкової сторінки повинна бути підібрана група пошукових запитів.
- Чи можна використовувати тільки ВЧ та СЧ?
Тільки ВЧ – ні. ВЧ та СЧ – теоретично так, але в цьому мало сенсу. Справа в тому, що потрапити в ТОП по СЧ та ВЧ молодому сайту не так вже й просто і на це потрібен час. Підключивши НЧ, ви зможете почати отримувати трафік набагато раніше. Цей трафік дозволить почати накопичувати поведінкові, а їх поліпшення дасть поштовх до зростання СЧ і ВЧ. Відповідно відмовляючись від цього типу запитів, ви ускладнюєте собі роботу.
- Ключі для SEO та контексту різні?
Не те, щоб різні – вони відрізняються за ступенем очищення. Якщо для SEO в одній групі ми залишаємо 5-15 ключів, то в одній групі для контексту їх може бути сотні. Тут вже не прибираються запити з різним порядком слів, з 0 показів та інші. Залишають все, що релевантно сторінці. Тобто, семантику для SEO з семантики для контексту зробити можна, навпаки – ні, потрібен новий збір. А налаштовувати контекст під ключі з SEO не ефективно, дуже багато буде втрачено.
Висновок
Стаття вийшла об’ємною і ми розібрали багато моментів, але це скоріше база. Дуже багато питань довелося або скоротити до пари речень, або взагалі пропустити. Хороший платний софт по можливості обходив стороною. Тому, якщо залишилися питання – пишіть в коментарях. А якщо хочете делегувати збір семантики нам – можете зробити замовлення на цій сторінці.
Якщо семантика у вас вже була підібрана, тоді вам більше підійде стаття про аналіз семантичного ядра.




