

Семантическое ядро – это та база, на основании которой строится вся работа по созданию и продвижению сайта. Если сперва создать сайт, а потом собирать ключи, скорее всего вы будете его переделывать. Если сделать сбор СЯ неправильно и начать продвижение, переделывать придется почти все. Поэтому лучше не доверять этот процесс никому, а делать самостоятельно.
Для примера – я собираю семантику уже 16 лет, для всех клиентских и личных проектов. И у меня нет желания передать ее на аутсорс. Потому что:
- Если семантик просто пропустит часть важный ключей – это еще куда ни шло. Хоть и не очень приятно продвигать сайт полгода, а потом получив от клиента вопрос «почему мы не прорабатываем запросы такие-то» не знать, что ответить.
- Если семантик включит в одну группу запросы, по которым результаты поиска кардинально отличаются, вы просто не сможете продвинуть одну страницу по всей группе. И потом придется создавать новые страницы. А это сильно увеличит срок продвижения, и многие заказчики не станут столько ждать.
- Если семантик сделает неправильную разгруппировку, и вы этого сразу не увидите, есть все шансы, что структуру сайта придется переделывать. Вопрос только в том, насколько далеко вы успеете зайти с неправильной структурой.
И это только часть проблем. Можно привести еще много «если» и подтвердить их примерами. За годы работы их набралось в избытке. Но не будем затягивать статью. Давайте разбираться, как правильно подбирать ключевые слова, чтобы потом не пришлось переделывать ни сайт, ни оптимизацию, не говоря уже про само семантическое ядро.
Термины и определения
Для начала разберемся, что такое ключевые слова, семантическое ядро сайта и частота поискового запроса. Только не стандартные определения, какой смысл писать то, что уже сотни раз написано, а простыми словами, чтобы был понятен смысл.
Ключевое слово – это то слово или фраза, которую пользователь вбивает в поисковую строку. Например, вы хотите заказать новый телефон. Открываете браузер и в поисковую строку Google или в адресную строку пишете «купить iphone». Это и есть ключевое слово. Называют его по-разному: поисковой запрос, ключевая фраза, ключевой запрос, ключ.
Семантическое ядро сайта (СЯ) – это список всех поисковых запросов, по которым он продвигается. Например, возьмем агентство PROSUVER и представим, что мы оказываем только 3 услуги: SEO-продвижение, консультации, аудиты. Если подобрать для каждой ключи и объединить в один список – это и будет СЯ для продвижения данного сайта.
Пример семантического ядра сайта в Excel:
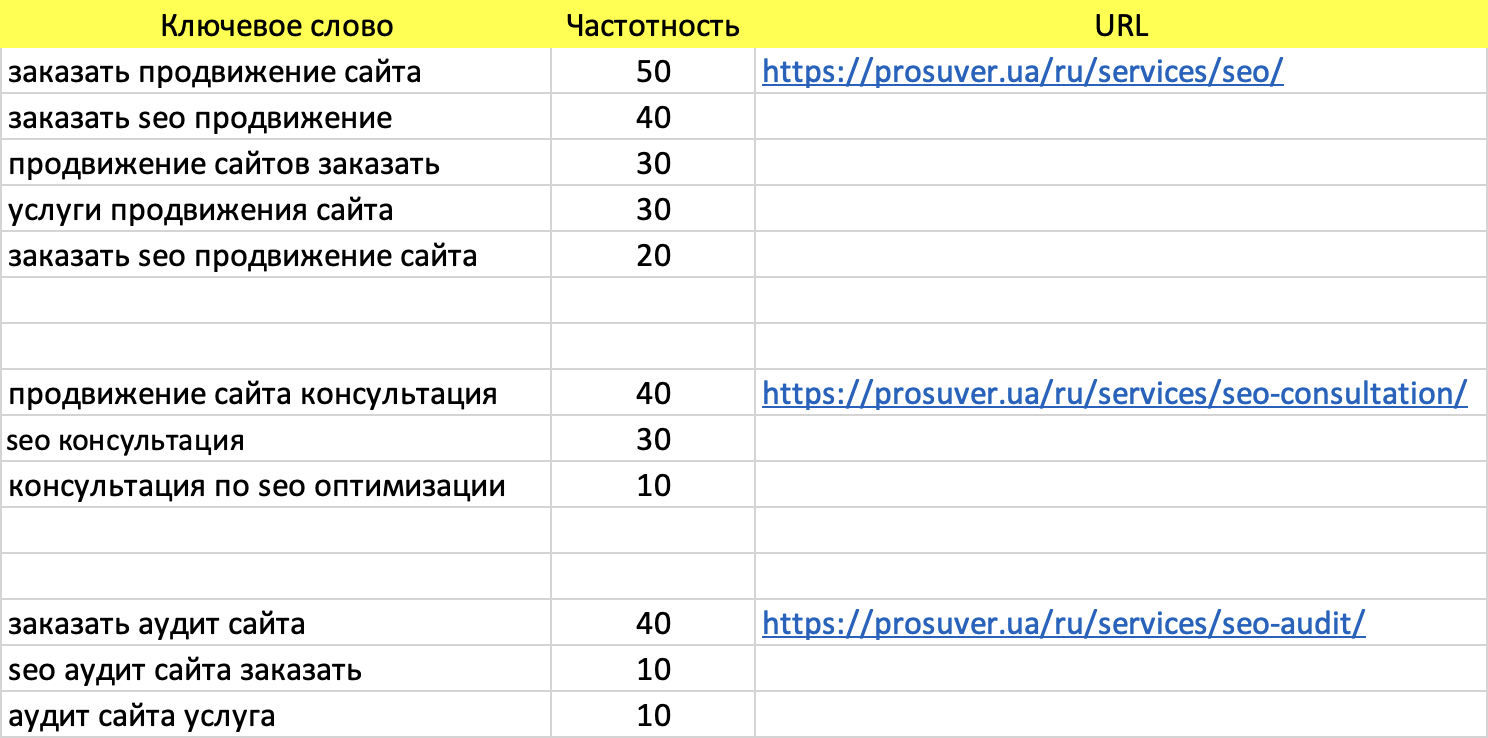
Кластеризация семантического ядра – это когда из одного большого списка ключевых слов делают небольшие группы и распределяют их по посадочным страницам. На практике это выглядит так – вы собрали скажем 500 поисковых фраз, после чистки их осталось 350. Все они потенциально подходят для продвижения вашего проекта, но вы не можете продвигать под них только одну страницу. Логично же, что пользователи, которые ищут аудит и консультацию должны видеть разные страницы. Соответственно вам нужно кластеризовать запросы – распределить их по разным группам. На скрине выше показано как это выглядит.
Посадочная страница – это любая страница, для которой отобраны поисковые запросы и которая участвует в продвижении. То есть, у вас может быть сайт на 100 страниц, но ключи вы подобрали только для 5 разделов и 10 товаров/услуг и пытаетесь продвинуть их. Так вот посадочных у вас будет всего 15, а не 100.
Частота ключевой фразы (частотность) – это то, сколько раз в месяц данную поисковую фразу вбивали в поисковую строку. В нашем случае речь будет идти про поисковую строку Google и частотность будем снимать для нее.
Сбор семантического ядра – это подбор ключевых слов для всего сайта, их чистка, кластеризация и распределение по посадочным страницам.
Виды поисковых запросов
Если вам нужно правильно собрать семантическое ядро для единственного проекта и больше вы этим заниматься не планируете, эту часть можно пропустить. Но если планируете развиваться как специалист в SEO или семантик, разобраться придется. Потому что часто будет попадаться вот такое: «ВЧ ВК запросы», «ключи СЧ НК».
По популярности
- Высокочастотные (ВЧ).
- Среднечастотные (СЧ).
- Низкочастотные (НЧ).
Как это выглядит в теории. Некоторые авторы статей, приводят цифры, которые теоретически должны помочь вам определить к какой группе относится тот или иной ключ. Например, больше 10 000 показов в месяц – это ВЧ, от 1000 до 10 000 – СЧ, менее 1000 – НЧ. Но это просто средние значения без привязки к конкретной ситуации. Какая вам разница, что монитор в среднем стоит 500$, если вы себе будете покупать за 200$ или 1000$?
Как это выглядит на практике. Цифры, которые позволяют отнести ключ к ВЧ, СЧ или НЧ индивидуальны для каждой тематики. Например, вы продвигаете небольшой бизнес по регулировке пластиковых окон в Киеве. Самый частотный ключ будет иметь 480 показов в месяц. Так вот, в данной конкретной нише это и будет ВЧ. Соответственно СЧ – это все что ниже его, но больше хотя бы 100 показов в месяц. А НЧ – менее 100.
Такой подход намного удобнее и практичнее. Потому что, если следовать теории, тогда вся ваша семантика состоит из одних НЧ. Но распределение по частотности важно не ради абсолютных цифр, а для того, чтобы выделить в конкретной нише наиболее и наименее важные поисковые фразы. Если этого не сделать, тогда получится, что:
регулировка пластиковых окон
ремонт регулировка пластиковых окон
Равнозначны. Но у первого частотность 480 показов, а у второго 10. И если мы оба отнесем к НЧ и будем выделять одинаковые усилия на продвижение, то второй выйдет в ТОП достаточно быстро, но не будет давать трафика, там его просто нет. А для первого нам не хватит выделенных ресурсов, он не станет в ТОП 1-3 и не будет давать трафика, хотя потенциал у него как раз есть.
Чтобы избежать таких ситуаций – в каждой нише определяется свой потолок для ВЧ и от него уже примерно определяем цифры для СЧ и НЧ.
По смыслу
- Коммерческие.
- Информационные.
- Смешанные (общие).
- Навигационные.
С навигационными проще всего – это запросы, по которым пользователь ищет не просто информацию или услугу, а хочет попасть на конкретный сайт. Например: «как правильно составить семантическое ядро prosuver». В данном примере пользователя интересует не ответ на вопрос в целом, ему нужна статья именно в блоге PROSUVER. Возможно, он читал ее ранее и теперь хочет прочесть еще раз.
Для SEO такие ключи почти бесполезны. Они станут в ТОП сами, специально работать с ними не нужно. Конечно, есть исключения, но это отдельная тема и не так часто встречаются в работе SEO-шника, чтобы расписывать их здесь. Поэтому, практически во всех случаях такие фразы убирают из семантического ядра.
Коммерческие ключевые слова – это фразы, по которым сразу видно, что пользователь хочет что-то купить. Пример: купить телефон, натяжные потолки цена. Если нужно составить семантическое ядро для интернет-магазина или сайта с услугами – отбираете именно их.
Информационные ключевые слова – это фразы, по которым пользователь ищет информацию. Пример: что такое семантика сайта. Отбираете их, если делаете ядро для блога или любого информационного проекта.
В принципе, все логично и не требовалось бы пояснений, если бы не запросы, по которым результаты поиска смешанные. То есть, в них есть и коммерческие сайты и информационные. Проблема в том, что новички часто не могут понять, в какие группы их включать.
Например, возьмем 3 фразы:
вывод из-под фильтра заказать
как вывести сайт из-под фильтра своими руками
вывод из-под фильтра
Первый – коммерческий и для него должна быть страница услуг. Второй – информационный и для продвижения по нему нужна статья в блоге. Третий – не понятно, пользователю нужна информация или услуга. И результаты поиска по таким ключам смешанные:
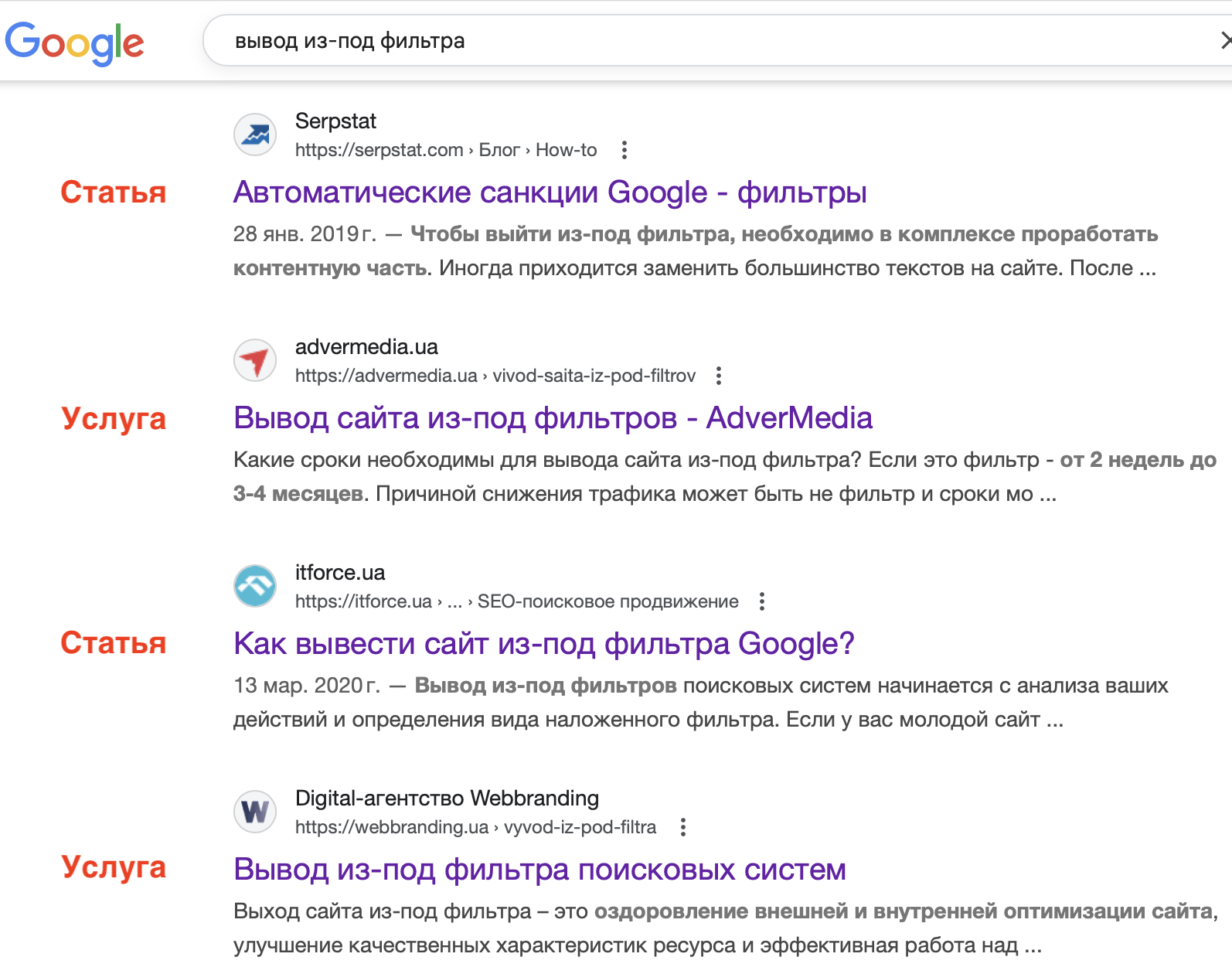
В таких случая нужно смотреть результаты поиска: если там большая часть коммерции – можно включать ключ в группу с коммерческими, если больше информационных – тогда в статьи. Если 50/50 – нужно оценивать свой сайт, конкурентов в ТОПе и плюс отдельно анализировать ТОП 3 или ТОП 5. Например, если 50/50, но первые 4 позиции занимают коммерческие проекты, тогда скорее всего и вам туда же. Но если в ТОПе очень «жирные» сайты с услугами (читай как «вложено много денег в ссылочное»), а ниже мелкие со статьями, возможно есть смысл бороться с последними, это будет реальнее.
В любом случае это важный момент. Ошибки здесь как раз и приводят к тому, что часть запросов из ядра ранжируется плохо. Это вызывает массу вопросов у клиентов и часто приводит к прекращению сотрудничества. А причина может быть не в плохой оптимизации, а в ошибках при распределении ключей по посадочным страницам.
По конкуренции
- Высококонкурентные (ВК).
- Среднеконкурентные (СК).
- Низкоконкурентные (НК).
Если вы новичок или ваша задача – только построение семантического ядра, а продвигать сайт будет кто-то другой, смело пропускайте этот блок. Определить уровень конкуренции не так уж просто, если никогда этого не делали. Да, это можно сделать с помощью некоторых инструментов, но из результаты малоинформативны для новичков.
Качественный анализ делается руками. Если захотите попробовать, начните с изучения статьи про анализ конкурентов. Затем возьмите запрос, который нужно проанализировать и посмотрите кто находится в ТОП 10. Сделайте сводную таблицу с показателями возраста, ссылочного, размера, качества наполнения и оптимизации страниц. Сравните со своей посадочной и сделайте вывод.
Такой анализ редко проводится на этапе поиска ключевых слов.
По региональности
- Геозависимые.
- Геонезависимые.
Геозависмые – это запросы, для которых поисковая система учитывает местонахождение пользователя. Например, результаты поиска для «заказать пиццу» в Киеве и Львове будут разными.
Геонезависимые – это запросы, для которых местоположение пользователя не имеет значения. Например: «как сделать скриншот», «iPhone16 отзывы».
Чтобы собрать семантику для сайта, информация о них вообще не обязательна. В большинстве случаев там все очевидно. Но знать про них нужно уже хотя бы потому, что вы можете находиться в одном городе, а клиент в другом. И результаты поиска у вас будут разные.
Часто это приводит к ситуации, когда ключ находится скажем на 2 позиции, а клиент видит его на 7. При этом сам он выехал за город и мониторит из соседней области. Избежать этого легко – позиции нужно снимать только в сервисах, которые позволяют все это настроить. Поэтому знать, что такой вопрос может поступить и как на него отвечать нужно.
Для чего нужно семантическое ядро
Готовое семантическое ядро, при условии, что оно правильно собрано, поможет примерно посчитать, сколько трафика вы сможете получать, сделать правильную структуру сайта и качественно его оптимизировать.
Оценить потенциал по трафику
Если у вас собраны все запросы, по которым будет продвигаться сайт, можно попробовать оценить сколько трафика в месяц он может давать. Для этого нужно сложить частотности всех поисковых запросов и поделить на 3. Это очень и очень грубый прогноз, но хотя бы порядок цифр вы уже будете знать.
Например, у вас в ядре 500 ключей. Просуммировали частотности и получили 30 000 показов в месяц. Если сможете вывести на 1-2 позицию все поисковые запросы, будете собирать процентов 30-35 кликов от общего количества показов. А значит, сайт сможет собирать до 10 000 переходов в месяц или порядка 330 в день. Эти цифры очень условны, многое зависит от конкретной выдачи – есть ли там контекст, сколько его, есть ли Google AI Overviews, насколько у вас привлекательны сниппеты и так далее. Исходя из практики – это вполне реальные цифры.
Если потенциальный трафик не устраивает и сайт еще не создан – можно принять решение расширить семантику, добавив новые товары или услуги. Или вообще отказаться от его создания. Если создан и вас не устраивал имеющийся трафик (при условии высоких позиций), такой анализ позволит понять – это уже потолок по трафику или еще есть куда расти.
Сформировать структуру сайта
Если вы хотите получить максимальный результат по SEO, структуру сайта нужно делать не на основании конкурентов и не так, как вам больше нравится. А на основании семантики. Конечно, конкурентов тоже можно и нужно анализировать, но только не копировать. Потому что, если они допустили какие-то ошибки в структуре, вы тоже их скопируете.
Например, вы подбираете ключевые слова для интернет-магазина. У вас есть ключи для 100 товаров – микро НЧ запросы по 10 показов, и для 10 разделов – СЧ и НЧ с количеством показов от 100 до 1000. Если не делать структуру и все страницы поставить на второй уровень, для ПС они будут равны по важности. Но какой в этом смысл? Вам же нужно сделать более приоритетными разделы и направить на них больше веса. А для этого и нужна правильная структура.
Поэтому, сперва собираете поисковые запросы, потом делаете кластеризацию, а уже потом смотрите какие группы у вас получились и как их структурировать. Пример части такой структуры для PROSUVER:
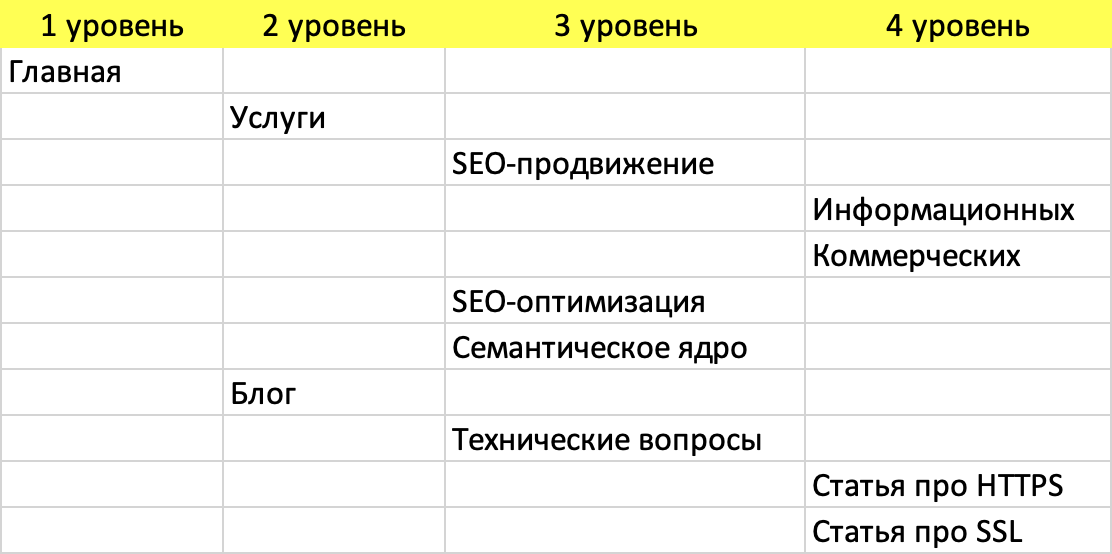
Сделать внутреннюю оптимизацию
Ну и главное, для чего нужны ключевые слова – это продвижение сайта. Вся внутренняя оптимизация строится на семантическом ядре:
- составление мета-тегов;
- доработка заголовков h1-h6;
- анализ и докрутка посадочных;
- оптимизация текстов;
- внутренняя перелинковка.
Ошибки в любом из этих этапов легко исправить. Но если неправильно собрана семантика и вы сделали все работы по ней, переделывать нужно будет практически все.
Внешняя оптимизация также строится на семантике, но это большая тема и о ней лучше почитать в отдельной статье: «Как правильно покупать ссылки для продвижения сайта».
Как подобрать ключевые слова для сайта
Составление семантического ядра начинается с подбора ключей. Сперва нужно правильно их собрать, потом почистить (через стоп-слова), снять частотности, почистить (убрать все с 0 показов), разгруппировать, еще раз почистить (уже внутри групп) и распределить по посадочным страницам. Конечный результат – это и будет СЯ. Разберем каждый этап.
Шаг 1. Собираем информацию
Что нужно знать перед подбором:
- регион продвижения;
- язык;
- основные услуги или товары;
- будет ли блог (если речь про коммерческие проекты);
- какие страницы наиболее важны.
Регион продвижений обязательно нужно уточнять. Ситуации бывают разные. Например, приходит на продвижение интернет-магазин, если посмотреть на контакты, страницу «О нас», будет понятно, что он работает по всей стране. Но заказчик хочет продвигаться только по Киеву, другие регионы его не интересуют. В таком случае частотности нужно будет снимать по Киеву и готовое СЯ может сильно отличаться от варианта под всю страну. А если вы сориентируетесь на страну, может оказаться, что важных запросов для Киева там нет, зато есть лишние, которые имеют смысл только при работе на страну. Эффективность продвижения снизится.
Уточнять язык нужно только для мультиязычных проектов. Нам часто приходится работать с сайтами на двух и более языках, владельцы которых заказывают продвижение на одном. Если это не уточнить может сложиться ситуация, что вы проработаете 2 языка и только на этапе согласования СЯ узнаете, что нужен был один. Это потеря времени, которую никто не будет оплачивать.
Основные товары и услуги вам понадобятся для того, чтобы понимать, что включать в ядро, а что нет. Если работаете с готовым проектом, нужно уточнить у владельца – на сайте представлен полный список продукции/услуг или он готов его расширять, при наличии спроса. Для сайтов на этапе разработки нужно запросить список продукции в любом виде, но только не на словах, чтобы потом не было «я такого не помню» и также обсудить возможность расширения.
Будет ли блог, раздел «Статьи», «Новости» или что-то подобное – это вам нужно знать, чтобы понимать оставлять ли в семантике информационные запросы (при проработке коммерческого проекта).
Какие страницы наиболее важны? Речь о том, что продающих страниц может быть много, но основную прибыль часто генерируют 20-30 товаров или 3-5 услуг. Если их знать, можно проработать их в первую очередь, чтобы быстрее получить результат.
Шаг 2. Составляем исходный список ключевых слов
Чтобы правильно собрать поисковые запросы, нужно составить список фраз, по которому будете делать парсинг в разных сервисах. Их называют исходными, базовыми, маркерными, якорными, стартовыми, начальными. Есть и другие названия, но все это одно и тоже.
Например, нужно собрать ключи для одной страницы, на которой продаются автомобили с вариатором. Исходные запросы могут выглядеть так:
То есть, мы знаем, что автомобиль – это еще и авто, и машина. Делаем комбинацию всех вариантов со словом «вариатор» и получаем уже какой-то список. Теоретически можно парсить по нему. Но можно сделать его более узконаправленным или расширить.
Например, если сайт коммерческий и информационные запросы ему не нужны (раздела со статьями не будет), тогда можно взять запросы выше и «обыграть» их со словами: купить, цена, недорого…
Это будет более узконаправленный список. По нему спарсится гораздо меньше фраз и их легче чистить, но есть риск потерять часть запросов. Например, в таком варианте после сбора вы скорее всего не увидите «авто вариатор в Киеве» – запрос коммерческий, но исходные ключи не позволят его спарсить. Чтобы не упустить такие фразы, парсинг нужно делать по более широкому списку (без «купить» и подобного). Тем не менее такой подход очень часто применяется при постраничном подборе ключей.
Что касается расширения – дело в том, что из головы очень сложно написать все варианты фраз, по которым нужно делать сбор, что-то обязательно забудете. Поэтому в нашем примере мы составили список самых очевидных фраз, а потом будем расширять его. Для этого берем один запрос из списка и смотрим результаты поиска:
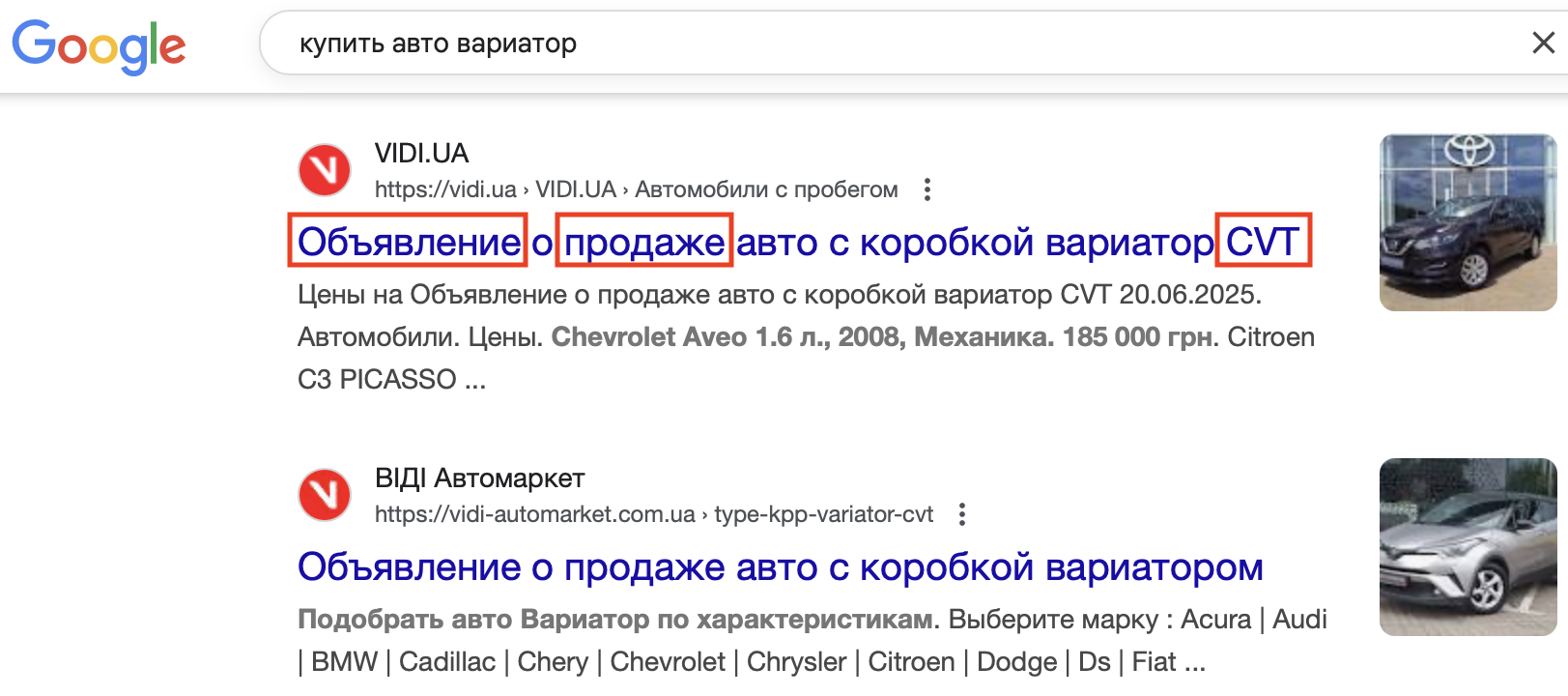
Видим, что вместо «вариатор» можно использовать «CVT», вместо «купить» — «продажа», а если у вас сайт с объявлениями, тогда и «объявления» можно добавить. И если попробовать расширить первый список, получим:
И если добавить в этот список еще и варианты со словами «купить», «цена», плюс расширить их фразами со словом «продажа», которое подсмотрели в выдаче, получим уже достаточно качественный список для парсинга. Дополнительно можно задействовать ChatGPT – он тоже может подсказать какие-то варианты.
Может возникнуть вопрос: зачем использовать «авто вариатор объявления» или «авто вариатор купить», если подобные запросы спарсятся по «авто вариатор». Теоретически так и должно быть. Но опыт показывает, что, если ограничиться только «авто вариатор», многих ключей со словами «купить», «объявления» в результатах вашего парсинга не будет. Поэтому список для парсинга лучше делать более подробным.
Пример фраз, которые не нужно использовать в нашем примере:
Первый ключ из неправильных слишком «широк» для данной страницы, по нему вы спарсите не только вариаторные, но и вообще любые авто. Запросов будет очень много и этим вы добавите себе работы по чистке. Второй ключ – это НЧ, который вообще вряд ли что-то позволит найти – много ли существует фраз, содержащих в себе эту…
Как это делать для одной страницы – мы рассмотрели. Но никто не будет собирать семантическое ядро для большого сайта постранично. Поэтому, прежде чем составлять такие списки, нужно посмотреть на сайт и выделить какие-то кластеры, для которых будете делать подбор. Например:
- Для малостраничного сайта (до 50 страниц) сбор лучше делать постранично. Он будет более качественным, риски потерять какие-то ключи минимальны. А затраты времени не настолько и большие.
- Для узкотематических проектов среднего размера можно делать сбор сразу для всего сайта. Делаете максимально большой список для парсинга, собираете ключи, возможно расширяете за счет конкурентов и получаете огромный список запросов, который потом кластеризуете.
- Для крупных и средних проектов с большим ассортиментом нужно выделять кластеры и работать с ними. Например, средний сайт по продаже телефонов может иметь кластеры по брендам: iPhone, Samsung, LG и так далее. Крупный интернет-магазин с бытовой техникой: стиральные машины, холодильники, пылесосы и так далее.
Количество таких кластеров зависит еще и от количества ключевых слов в целом. Например, в той же технике Apple их очень много и там нет смысла выделять в один кластер все iPhone. Запросов будет огромное количество и разбирать их потом неудобно, гораздо проще делать подбор по моделям. Если же вы делаете сбор по автомобилям какой-то не очень популярной марки, то здесь уже можно собирать сразу по всей марке и потом кластеризовать, просто потому что запросов намного меньше.
Проработка в таком случае будет поэтапная. Взяли один раздел – проработали, взяли второй – проработали, и так весь сайт. Есть только один минус – если проект слишком крупный, это может занять много времени. В таком случае вам и понадобятся наиболее важные страницы/товары/разделы. Уточнили у клиента, что для него приоритетно – проработали и поставили сбор СЯ на паузу. Оптимизируете данные страницы и потом продолжите сбор. А в это время Google уже начнет индексировать изменения и может появится первая динамика по позициям.
Если коротко:
- Смотрите сайт и разбиваете его на кластеры.
- Выбираете один и составляете для него фразы, по которым будете делать парсинг.
- Расширяете этот список за счет результатов поиска Google, ChatGPT, сервисов для подбора запросов, конкурентов.
- Прорабатываете и начинаете следующий кластер.
Шаг 3. Парсинг
Теперь нужно сделать парсинг ключевых слов по тем спискам, которые вы составили. Источников и сервисов для парсинга много, но они не используются одновременно все. Не будете же вы оплачивать 5 сервисов для сбора семантического ядра, если они во многом дублируют друг друга. Подбирать их нужно под конкретную задачу и ваш бюджет. В этой статье приведу несколько вариантов, которых будет достаточно для сбора СЯ большинства сайтов при продвижении в Google.
Источники ключевых слов
- Поисковые запросы.
- Поисковые подсказки.
- Конкуренты.
Поисковые запросы – это то, что пользователи вбивают в поисковую строку браузера. Их собирает, подсчитывает частотности и хранит поисковая система. В нашем случае Google. Это первое что нас интересует.
Поисковые подсказки – это то, что предлагает поисковая система, когда вы вводите запрос в поисковую строку:
Семантическое ядро конкурентов – это список запросов, под которым они продвигаются. Именно его мы узнать не можем. Но можем узнать запросы, по которым пользователи находили в поиске их сайты и переходили на них. Иногда анализ конкурентов может дать много ключей, которые не получится получить из первых двух источников.
Какие сервисы использовать
Если источников нужно как можно больше, чтобы СЯ было более полным, то сервисов как можно меньше, чтобы уменьшить расходы на софт. Поэтому я покажу очень небольшой набор из того, чем пользуюсь сам. Это не значит, что данное решение единственно правильное, но оно позволит собрать семантику на очень высоком уровне без слишком больших затрат.
Какие сервисы для поиска ключевых слов можно использовать:
- Google Keyword Planner;
- Google Search Console и Google Analytics;
- Serpstat;
- Ahrefs;
- Keyword Tool;
- SemRush;
- SE Ranking.
Это далеко не полный список. Но даже из него мы будем использовать только первые 4. Да и то, Ahrefs можно было бы исключить, но он нужен для анализа ссылок, поэтому есть у большинства SEO-шников. А если так, какой смысл его игнорировать. На этапе сбора лишних ключей не бывает.
Google Keyword Planner (это Планировщик ключевых слов в Google Ads) используется практически всегда. Он показывает именно те запросы, которые пользователи вбивают в поисковую строку Google и частотности по ним. Он бесплатный и не требует дополнительных программ и сервисов. Чтобы работать с ним, нужно создать аккаунт в ads.google.com, создать первую рекламную компанию (не оплачивая), затем открыть сам Планировщик:
https://ads.google.com/aw/keywordplanner/home
Google Search Console и Google Analytics используются когда у вас есть к ним доступ и сайт имеет какой-то трафик. Не подходит для проектов без трафика или при сборе семантического ядра на этапе разработки. Если проект ваш – добавляете его в Search Console, подключаете Аналитику, ждете пока обновятся данные и можно будет использовать. Если клиентский – просите владельца делегировать права и работаете. Ссылки не даю, они легко гуглятся, там сложно ошибиться.
Serpstat и Ahrefs – это платные сервисы, которые помогут узнать ключевые слова конкурентов. На самом деле возможностей у них намного больше. Но я пытаюсь показать минимальный набор действий, чтобы не перегружать статью, но и не снижать качество будущего СЯ. Если вам нужен только сбор семантики для сайта, и вы не собираетесь его продвигать – тогда Serpstat будет достаточно. Если вы SEO-шник, да еще и не новичок, Ahrefs у вас скорее всего уже есть, в таком случае используйте и его тоже.
Какой подход выбрать в зависимости от сайта
Какие сервисы использовать и какой подход выбрать зависит от сайта и цели. Перечислю то, с чем будете сталкиваться чаще всего.
Новый сайт (на этапе разработки или только создан):
- Парсите: поисковые запросы, подсказки и конкурентов.
- Понадобиться: Планировщик, Serpstat.
- Способ сбора: делаете одну большую группу, которую потом будете разгруппировывать.
Рабочий сайт со сформированной структурой и трафиком:
- Парсите: поисковые запросы, подсказки и статистику. Конкурентов добавляем только при необходимости.
- Понадобятся: Планировщик, Google Search Console, Google Analytics, Serpstat.
- Способ сбора: собираете постранично (для мелких сайтов) или по разделам (для средних).
Крупный сайт с большим трафиком:
- Парсите: статистику.
- Понадобятся: Google Search Console, Google Analytics.
- Способ сбора: собираете всю статистику в один большой список, удаляете запросы с частотностью менее 50 показов (цифра варьируется в зависимости от проекта), и те, которые находятся на 1-2 позиции или дальше 20-30. Остальные распределяете по посадочным и продвигаете.
Последний подход позволяет увеличить трафик крупного проекта в минимальные сроки. Если начнете с полного ядра, до продвижения можете добраться и через полгода. А это обычно недопустимо. И только после того, как результат будет достигнут, можно собирать всю семантику, да и то блоками. Например, собрали «бытовую технику» со всеми вложенными стиральными машинами, микроволновками и прочим, проработали внутреннюю оптимизацию раздела и только после этого берете следующий.
Пример парсинга
Давайте посмотрим, как процесс сбора выглядит на практике. Я расписываю на примере одной страницы/раздела для 1 группы исходных ключевых слов. Если у вас их много, повторяете для каждой отдельно и результаты заносите в Excel (1 группа – 1 столбец).
Допустим мой список для парсинга выглядит так:
семантическое ядро
ключевое слово
поисковый запрос
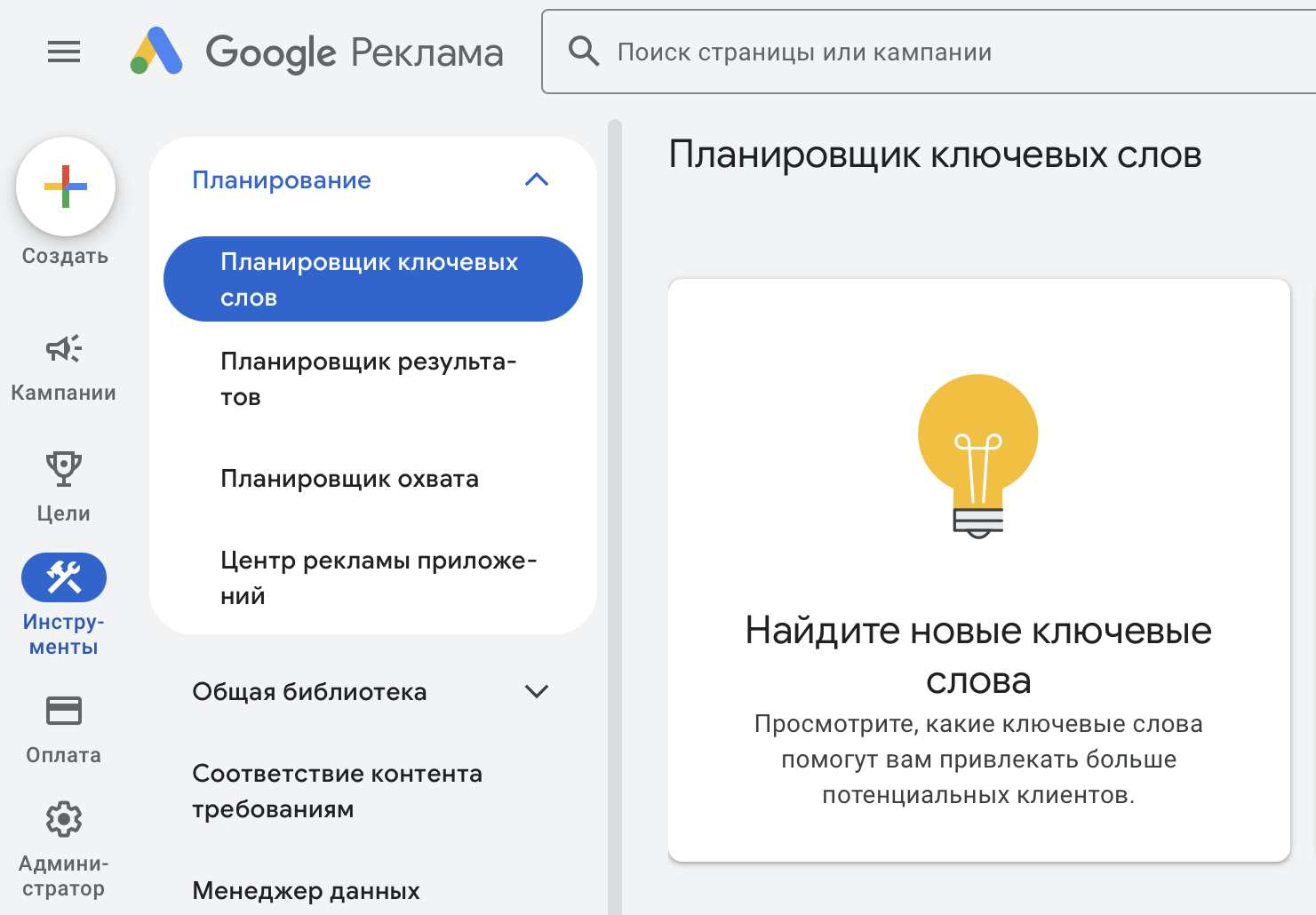
Открываем Excel и переносим в столбец «А» этот список. Открываем Google Keyword Planner, нажимаем «Найдите новые ключевые слова»:
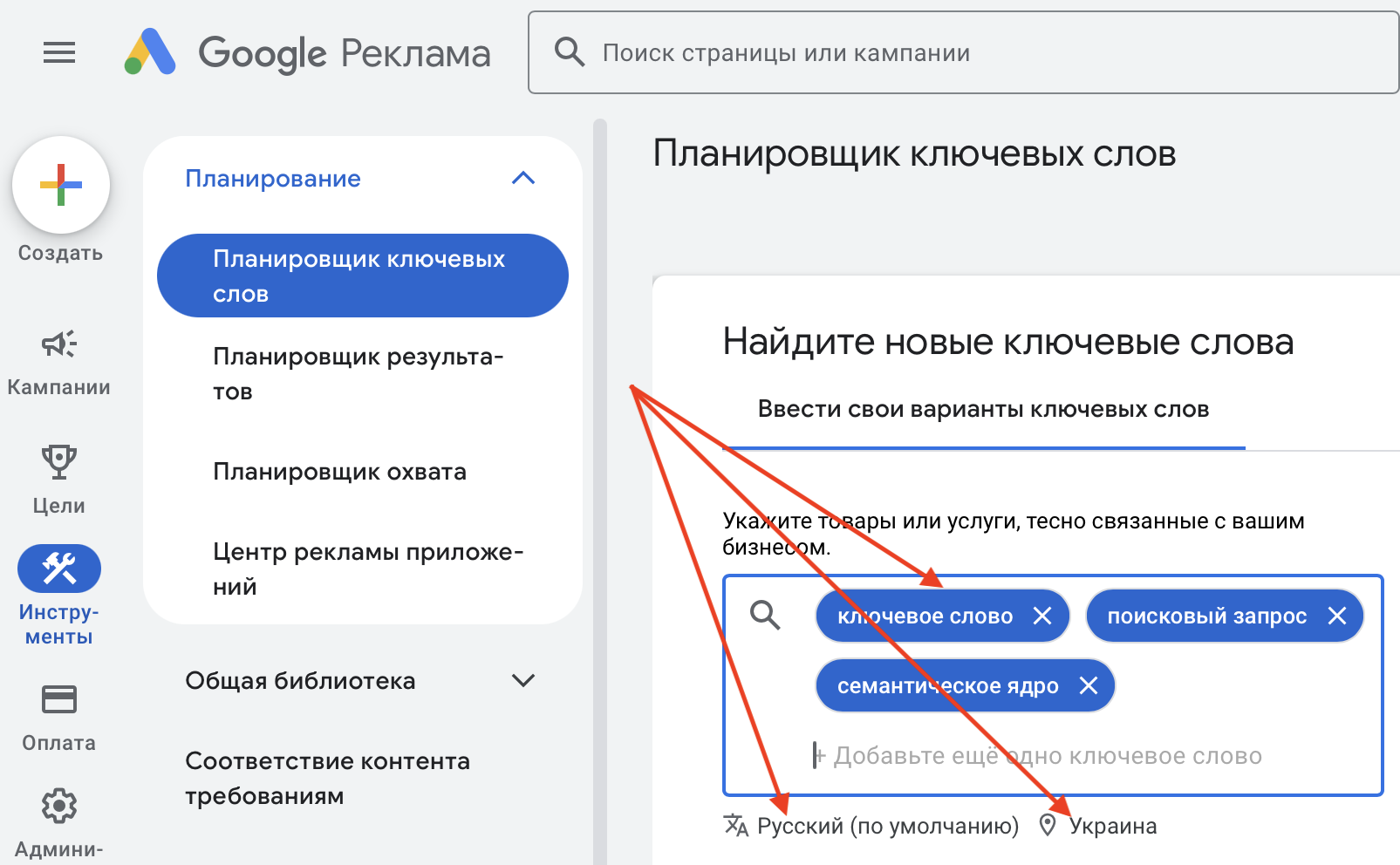
Вставляем список для парсинга, выбираем регион, для которого делаем сбор, и язык:
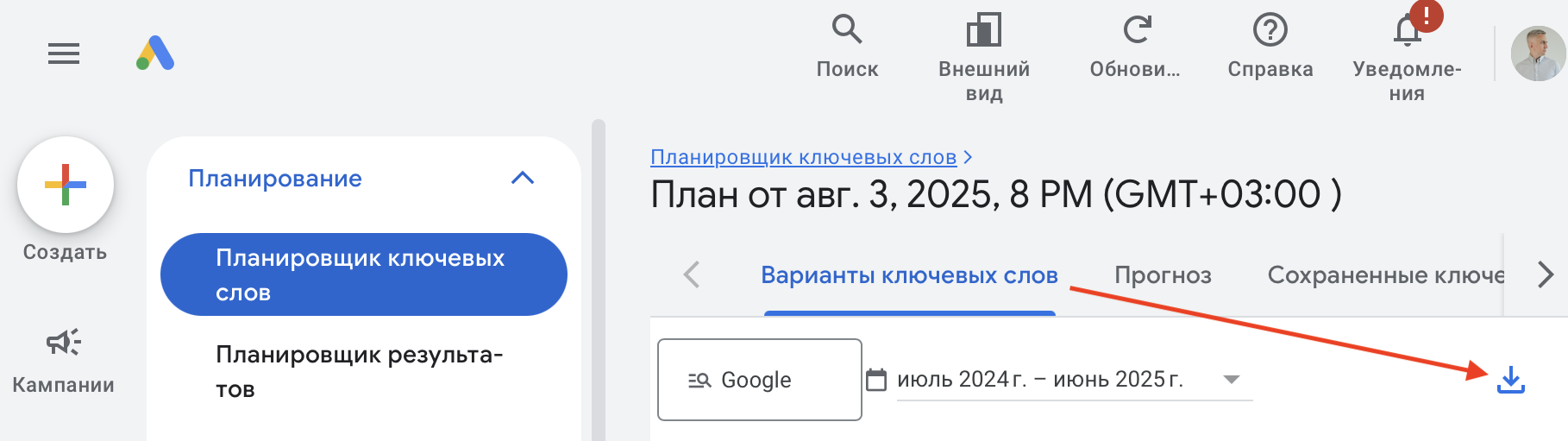
Нажимаем «Получить результаты» и в следующем окне скачиваем результаты подбора, нажав сюда:
Открываем полученный файл, копируем только список ключевых слов из первого столбца и вставляем их в столбец «А» того документа Excel, который создали выше, назовем его «рабочий». Планировщик можно закрывать.
Теперь соберем поисковые подсказки через Serpstat. Авторизовываемся, открываем «Анализ ключевых слов – Поисковые подсказки», выбираем страну, вводим первый запрос из нашего списка исходных:
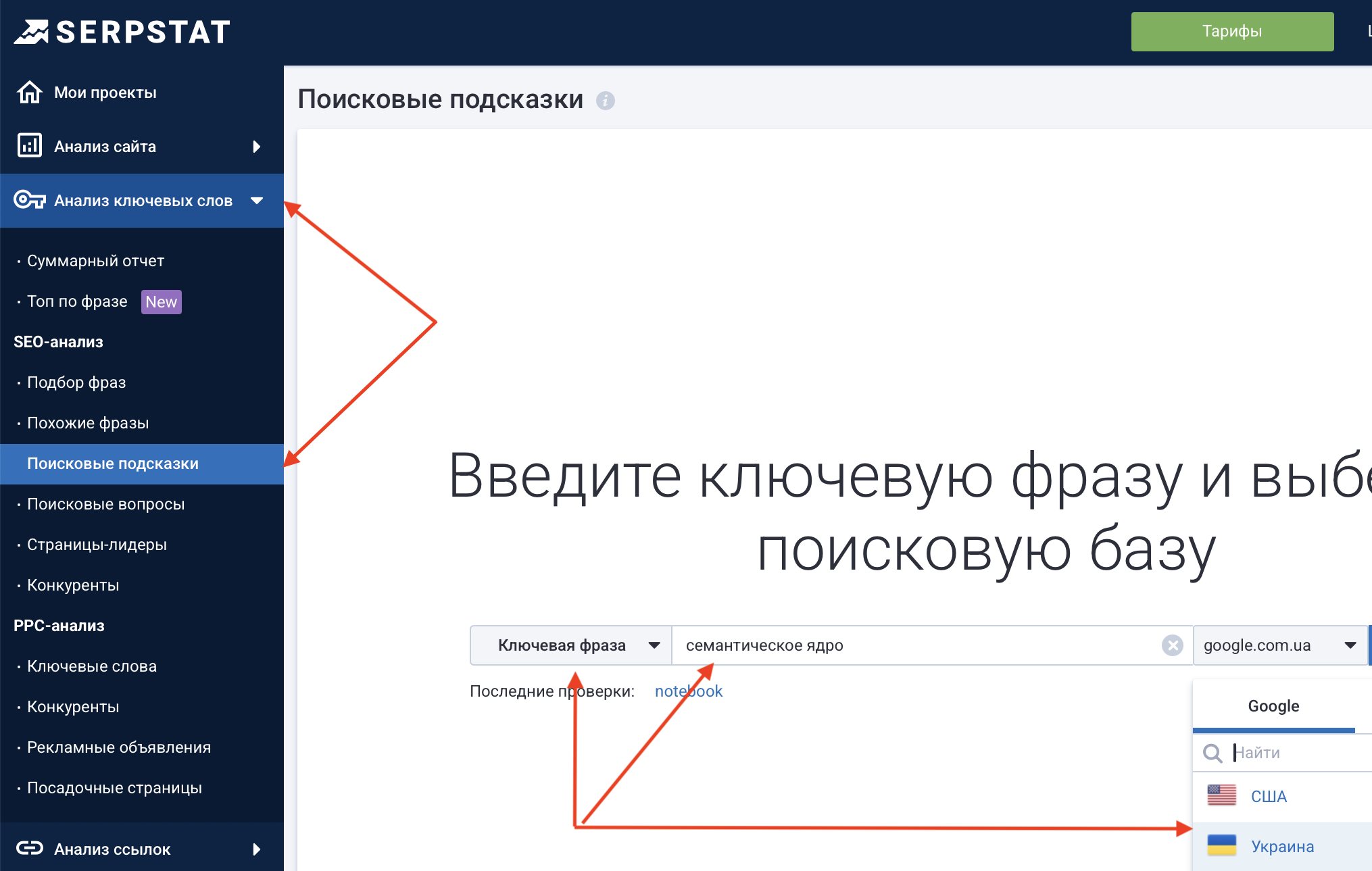
Нажимаем «Найти», открывается страница с результатами подбора. В правом верхнем углу нажимаем на «Экспорт» и скачиваем файл в любом удоном формате. Открываем файл и также попируем из него все подсказки в столбец «А» рабочего Excel. Затем повторяем все шаги для оставшихся двух фраз из исходного списка.
Обратите внимание, в боковом меню есть еще и «Поисковые вопросы» — это тоже полезный инструмент, но нужен не всем и не всегда. Если делаете постраничный подбор и на продвигаемой странице уместно использовать блок с вопросами – добавляйте и их.
Осталось посмотреть ключевые слова конкурентов. Это можно сделать и в Serpstat, но для разнообразия воспользуемся Ahrefs. Есть 2 варианта:
- Авторизоваться в Ahrefs, открыть «Keywords Explorer», вписать первую исходную фразу и в открывшихся результатах посмотреть ТОП 10 страниц по данной фразе и переходя по ссылкам посмотреть ключи, по которым они ранжируются.
- Самостоятельно изучить результаты поиска в Google, выбрать лучшие страницы и проверять уже то, что больше всего понравилось.
Проще первый, лучше второй. Почему так? Результаты поиска по разным фразам из исходного списка могут отличаться, а значит, чтобы получить более полную картину придется проверять их все, выбирая неповторяющиеся сайты. Плюс в смешанной выдаче половина страниц вообще должна быть отброшена и оставшихся может не хватить. Поэтому лучше взять 1 запрос и посмотреть по нему ТОП 20-30, открыть каждую страницу, оценить, насколько она совпадает с тем, что вам нужно и отобрать для анализа несколько действительно подходящих.
Например, вы собираетесь писать статью «Как правильно составить семантическое ядро». Начинаете анализировать результаты поиска и видите, что часть из них – это страницы каких-то сервисов, еще часть – это услуги. Зачем вам собирать их ключи? В таком случае вам нужно выбрать несколько качественных статей и анализировать их.
Когда список url-адресов будет готов, авторизовываетесь в Ahrefs, открываете «Site Explorer», вводите первый url, и выбираете «Exact URL»:
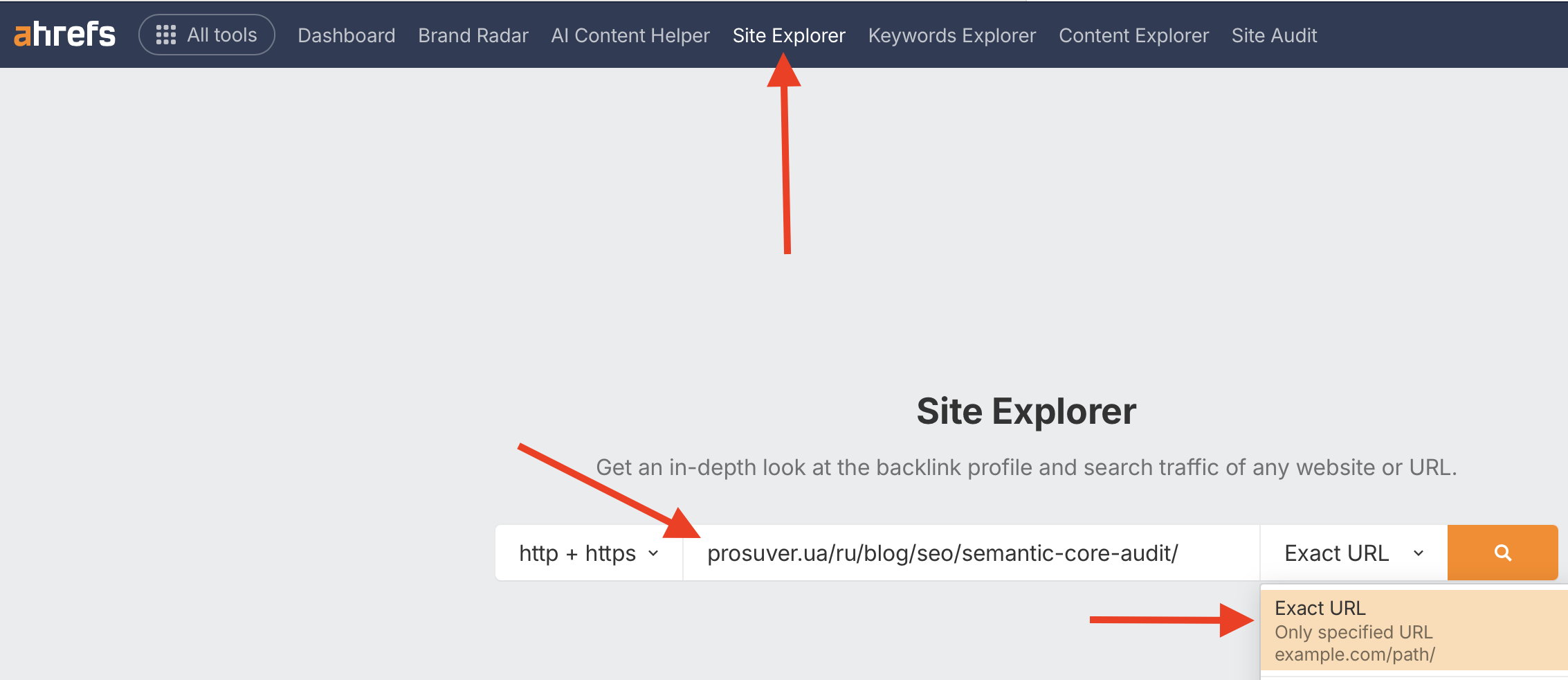
Нажимаете на оранжевую кнопку с лупой и в открывшемся окне в боковом меню выбираете «Organic keywords»:
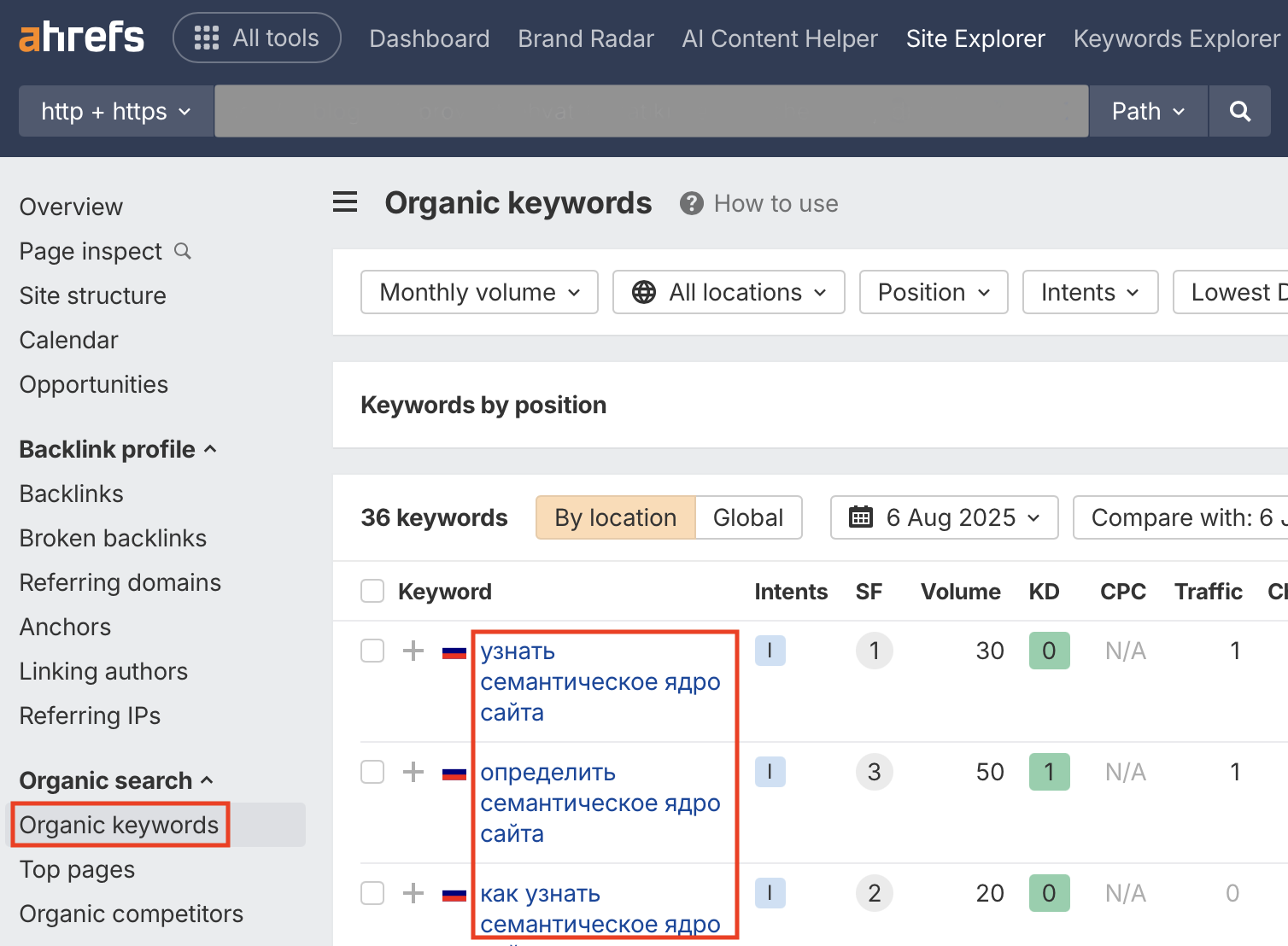
Это и будут ключевые слов конкурента. Скачиваете через кнопку «Export» в правом верхнем угла, переносите их в рабочий Excel и проделываете тоже самое со всеми отобранными страницами.
В большинстве случаев на этом сбор останавливаем. Но если вам нужно собрать ключевые слова для сайта (а не страницы/раздела) и есть возможность скачать данные из Google Аналитики или Search Console, тогда открываете их и скачиваете еще и оттуда. Хотя для нашего примера в этом мало смысла, потому что мы сейчас разбираем одну группу, а из этих сервисов вы скачаете поисковые запросы сразу для всего сайта.
Поэтому подробно разбирать не будем, там ничего сложного. Например, в Google Search Console нужно просто открыть раздел «Эффективность» и экспортировать все ключи:
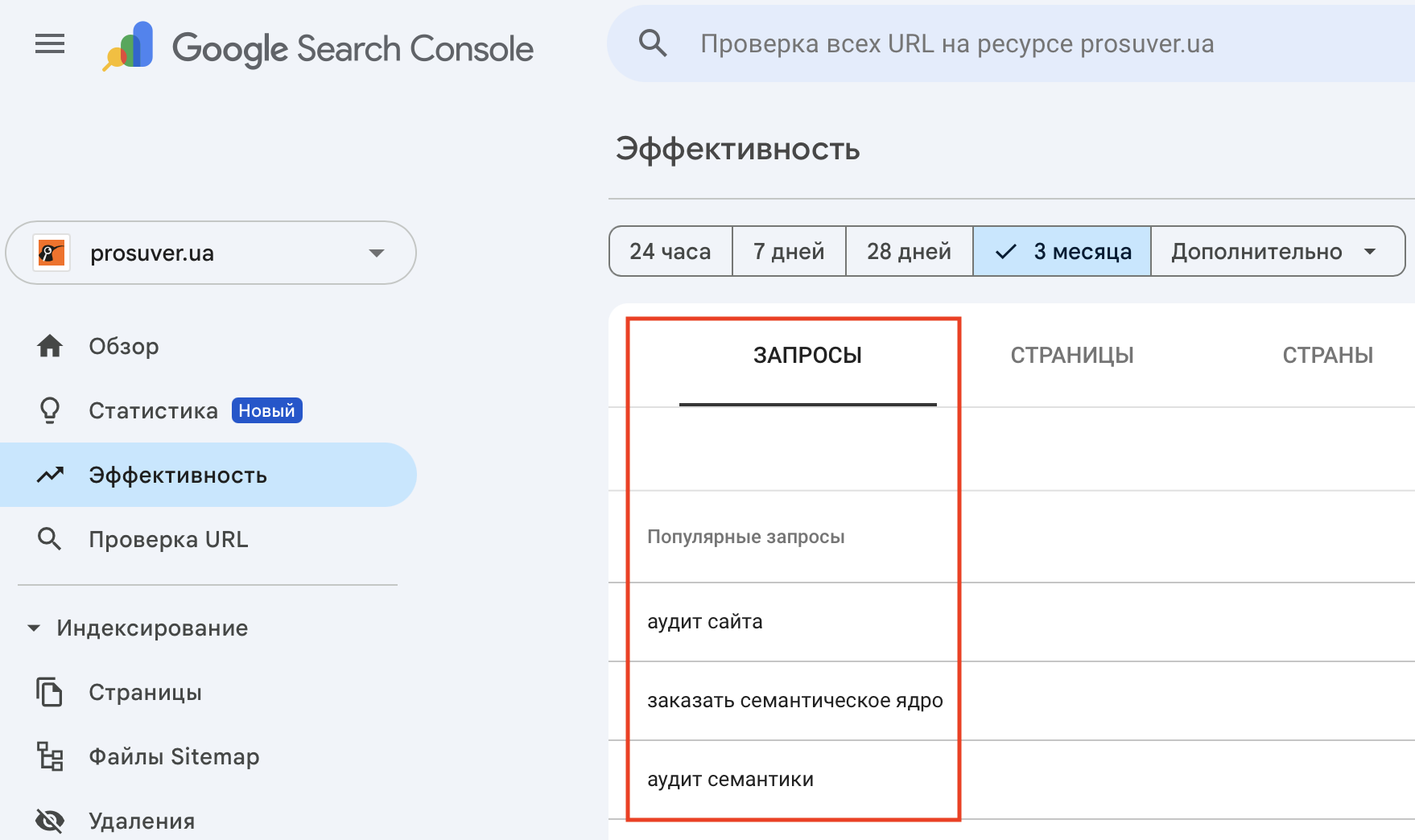
С Google Аналитикой работать немного сложнее и, если у вас нет опыта работы с ней, пропускайте. Того, что собрано уже достаточно.
После всех шагов у вас в Excel будет один столбец с большим количеством фраз. Причем количество может варьироваться от десятков до десятков тысяч. Так что пусть вас не пугает количество строк. На этом подбор ключевых слов закончен. По крайней мере для одной группы или страницы. Теперь повторяете его для остальных групп или страниц (заполняете столбы B, C… в Excel) и переходите к следующему этапу. А если сбор делали для всего сайта сразу, тогда повторять ничего не нужно.
Шаг 4. Чистка
Лучший способ чистки ключевых слов – прочитать все фразы, которые вы отобрали, и удалить лишние. Например, у вас страница по продаже кухонных столов. Вы же понимаете, что «купить стол для кухни» – это подходящий ключ, а «как сделать кухонный стол своими руками» – нет. Подумать заставляют только варианты вида «кухонный стол», где непонятно, что пользователь ищет – товар или информацию. Но это мы уже разобрали выше – делаете анализ результатов поиска и принимаете решение.
Если после парсинга в вашем списке в Excel хотя бы до 1000 строк, можете смело идти по этому пути. Вычитываются они достаточно быстро и риски потерять что-то важное почти отсутствуют.
Если речь про тысячи или десятки тысяч – чистка семантического ядра делается как минимум в 2 этапа: предварительная (грубая) и окончательная (финальная). Финальную лучше делать вместе с кластеризацией. А сейчас разберем, как очистить поисковые запросы от совсем уже неподходящих слов и разного мусора.
Стоп-слова
Если составить хороший список стоп-слов, можно в несколько кликов сократить десятитысячный список напарсенных ключей до 2-3 тыс. Чтобы составить такой список, нужно открыть рабочий Excel и рядом любой текстовый редактор. Далее начинаете вычитывать спарсенные запросы и, если они содержат какие-то слова, которые точно делают их неподходящими для вас – переносите эти слова в текстовый редактор.
Например, у нас статья «Как собирать семантическое ядро», для которой мы и делали сбор. Если при чистке видим: «заказать СЯ» – копируем слово «заказать» в текстовый редактор, потому что любые фразы, которые его содержат, нам не подойдут, они коммерческие. Или «как собрать семантику для контекста» – копируем слово «контекста», потому что там нужен немного другой подход и нет смысла описывать его в одной статье с подбором под SEO. Или из «анализ поисковых запросов ютуб» берем «ютуб». И так далее.
Список стоп-слов будет выглядеть так:
купить
заказать
цена
стоимость
недорого
дешево
ютуб
контекст
…
Основной вопрос – сколько вычитывать? Если у вас в рабочем Excel тысяч 10-20 строк, не нужно читать их все. Прочтите или первые несколько сотен или просто скрольте произвольно документ и выписывайте, что бросилось в глаза. Например, проскролили произвольно несколько десятков строк, выписали что увидели, еще несколько десятков или сотню – выписали и так далее.
Но если делаете подбор для крупного проекта с большим количеством однотипных страниц и большим количеством ключей, есть смысл заморочиться и постараться вытянуть максимальный список стоп-слов из первой группы. Пусть вы потратите на это много времени, зато потом сэкономите его очень много на других страницах. В таком случае вычитать лучше сразу несколько тысяч строк или даже все фразы из первой группы.
Когда список готов, нужно воспользоваться каким-то софтом, сервисом или скриптом, которые позволят загрузить список ключевых слов, список стоп-слов и нажав на одну-две кнопки получить список запросов без стоп-слов. Вариантов как это сделать много, но в основном они платные. В данной статье я их не буду затрагивать, чтобы и не растягивать, и не переплачивать. Покажу максимально простой и бесплатный вариант:
- открываете Google Таблицы;
- создаете 3 вкладки: Keywords, Stop words, List after cleaning (названия на ваше усмотрение);
- в меню Google Таблиц открываете «Расширения — Apps Script» и добавляете код:
function cleanList() {
var ss = SpreadsheetApp.getActiveSpreadsheet();
var keywordsSheet = ss.getSheetByName("Keywords");
var stopWordsSheet = ss.getSheetByName("Stop words");
var cleanedSheet = ss.getSheetByName("List after cleaning");
// Получаем данные
var keywordsData = keywordsSheet.getRange(1, 1, keywordsSheet.getLastRow(), 1).getValues().map(r => r[0]);
var stopWordsData = stopWordsSheet.getRange(1, 1, stopWordsSheet.getLastRow(), 1).getValues().map(r => r[0].toLowerCase());
// Фильтрация
var result = keywordsData.filter(q => {
var lowerQ = (q + "").toLowerCase();
return !stopWordsData.some(stop => lowerQ.includes(stop));
});
// Вывод результата
cleanedSheet.clear();
cleanedSheet.getRange(1, 1, result.length, 1).setValues(result.map(r => [r]));
}- сохраняете и возвращаетесь в Google Таблицы;
- на вкладке «Keywords» делаете «Вставка — Рисунок — Фигура», добавляете прямоугольник или любую фигуру, и подписываете «Clean list» или как вам нравится – это просто кнопка, которую будете нажимать, чтобы получить результат;
- нажимаете на созданной кнопке правой кнопкой мыши, выбираете «Назначить скрипт» и вписываете:
cleanList
На этом все. Вставляете список поисковых запросов из рабочего Excel на вкладку «Keywords», стоп-слова на вкладку «Stop words», нажимаете на кнопку «Clean list» и на вкладке «List after cleaning» получаете уже почищенный список запросов. Переносите его в рабочий Excel, на отдельную вкладу (вдруг где-то ошиблись, чтобы потом не делать парсинг повторно).
Частотности
Поскольку количество фраз значительно сократилось, теперь можно снять частотности с оставшихся и удалить те, которые имеют 0 показов в месяц. Это может сократить ваш список еще в 2-3 раза и более. Можно было бы и раньше снять частотности, но тогда пришлось бы сильно переплатить.
Здесь также есть удобные платные решения. Но пока рассмотрим бесплатный вариант. Открываете Планировщик ключевых слов, но выбираете не «Найдите новые ключевые слова», а «Посмотрите количество запросов и прогнозы»:
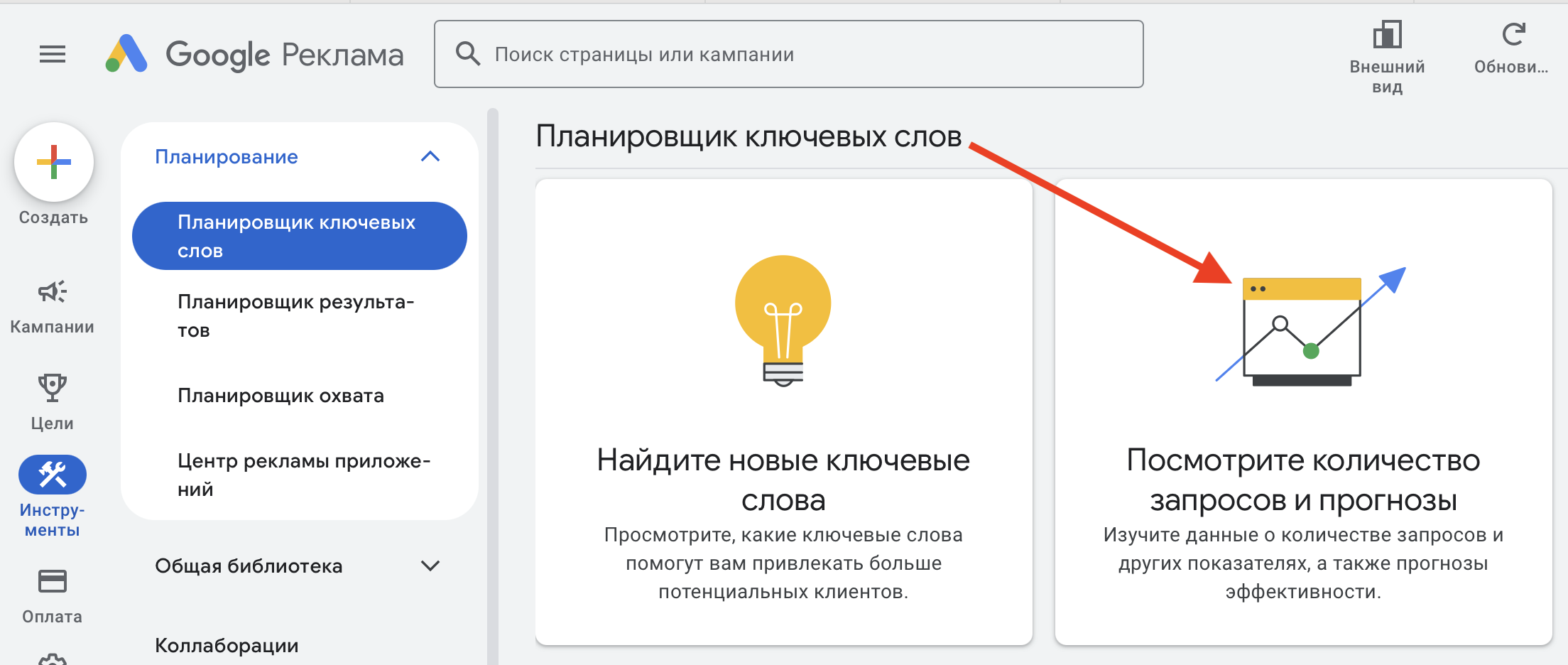
Дальше все по аналогии с подбором – вставляете почищенные стоп-словами запросы, нажимаете «Начать», указываете страну и язык. Экспортируете полученные результаты.
Открываете экспортированный файл в Excel, затем «Данные — Сортировка» и настраиваете сортировку в порядке убывания частотности. Удаляете все строки с 0 показов. Оставшиеся ключи с частотностями переносите в рабочий Excel.
На этом предварительная чистка окончена.
Шаг 5. Кластеризация
Кластеризация ключевых слов требует разных подходов для разных исходных данных. Я покажу несколько распространенных моментов.
Если сайт хорошо ранжируется
Если вы прорабатываете сайт с хорошими позициями – тогда нужно снять позиции и в рабочий Excel добавить столбцы с позициями и страницами, которые ранжируются по этим ключам. Затем сделать сортировку ключевых слов (через фильтр) по столбцу «Страница» от А до Я. В результате должно получиться вот так:

Затем разделяете группы с одинаковыми url-адресами парой пустых строк и получаете готовые группы ключей и сразу посадочные страницы для них. Если запроса нет в ТОП 100 и позиция по нему не снялась – убираете его или по смыслу переносите в подходящую группу.
И вот здесь уже нужна будет финальная чистка. Каждую группу нужно будет внимательно вычитать и удалить все что не подходит.
В зависимости от цели и текущих позиций сайта с таким ядром можно работать очень гибко. Например, оставить только те фразы, которые уже находятся в ТОП 5-20 и работать с ними. Что даст максимально быстрый результат по трафику. Или, наоборот, максимально расширить семантику, чтобы выстроить стратегию продвижения на длительный период.
Если сайт не ранжируется
Здесь уже не принципиально – сайт на этапе разработки или новый/старый без трафика. Если кластеризация поисковых запросов по релевантной странице невозможна, значит сортировку нужно делать по смыслу.
Например, у вас проект по продаже цветов. Можно сделать группировку запросов по их видам. Выбрали все, где есть упоминание роз в одну большую подгруппу и работаете с ней. Делаете финальную чистку и потом распределяете фразы по смыслу:
купить розы
магазин купить розы
купить розы цена
купить красные розы
цветы розы красные купить
синие розы купить
синие розы купить доставка
Параллельно с этим заводите в рабочем Excel еще один лист, называете его «Структура» и начинаете формировать будущую структуру сайта (если она еще не сделана):
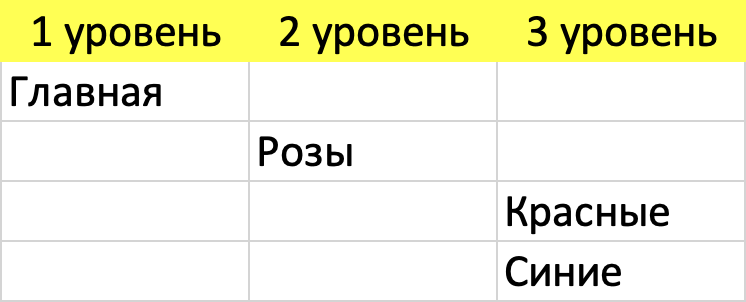
Такая группировка семантического ядра занимает действительно много времени и некоторые пытаются автоматизировать процесс используя различные сервисы. Такой подход иногда применять можно, но только не в том случае, когда у вас почти нет опыта. И не в том случае, когда вам нужно действительно правильное семантическое ядро, с которым можно выстраивать долгосрочную стратегию. Если кратко: нужно высокое качество – делайте руками.
На что обратить внимание
1. Релевантность ключевых слов
Нужно убедиться, что запросы, которые вы отбираете, релевантны странице. Например, те же розы. Если работаете с интернет-магазином по продаже букетов, то запрос «купить розы» вам может и не подойти. Потому что большая часть сайтов в ТОП 10 может продавать саженцы, а у вас букеты. Соответственно такой ключ требует анализа или удаления из СЯ.
2. Не нужно ли разделить группу
Иногда в одну группу могут попасть запросы, по которым нужно продвигать разные страницы. Например:
купить внедорожник
купить внедорожник дизельный
купить внедорожник б/у
Если посмотреть результаты поиска по первым двум – они абсолютно разные. И если вы хотите высокие позиции по обоим ключам – нужно делать отдельные посадочные. Третий запрос также имеет свою выдачу, больше заточенную на доски объявлений и онлайн-авторынки. В то время как по первому могут больше ранжироваться салоны или выдача будет смешанная, что тоже потребует анализа. То есть, они может и похожи, но страницы будут разные. А даже если где-то и одинаковые, то в таких спорных моментах вы должны обязательно в этом убедиться, сделал соответствующий анализ.
3. Синонимы должны быть объединены на одной странице
Речь о том, что нет смысла писать 2 отдельные статьи вида: «Как подобрать семантическое ядро» и «Как подобрать ключевые слова». Да, можно под каждую собрать свою семантику, сделать разную структуру статей, по-разному их написать, оформить. Но это одно и то же. И если 10 лет назад Google мог дать трафик на обе, то сейчас при большом количестве подобных смысловых дублей вы скорее получите понижение позиций.
Часто задаваемые вопросы
- Сколько запросов нужно включить в СЯ?
В среднем группа ключей для 1 посадочной страницы включает 5-15 запросов. Иногда это может быть 1-2, а иногда доходить до 25-30, но это при условии их однотипности.
Количество групп в СЯ не ограничено. Лишь бы вы могли это обработать. Потому что, если собрать 10 000 ключей и потом несколько лет прорабатывать под них страницы – это будет не лучшая идея…
- Что делать с ключевыми словами с ошибками?
Если по ним высокие частотности – обязательно оставляем в ядре и отслеживаем по ним позиции. Есть спрос – это нужно использовать. Но при оптимизации страниц применяем только слова без ошибок и правильные речевые обороты.
- Что делать с фразами, у которых разный порядок слов?
Речь про «купить холодильник недорого» и «купить недорого холодильник». Для Google это могут быть разные фразы с разным количеством показов. Поэтому здесь нужно ориентироваться на то, для чего вам семантика. Если вы делаете ее на этапе разработки проекта, и СЯ вам нужно чтобы оценить потенциальный трафик и объем ниши, тогда оставляете оба варианта. Если это обычное ядро для продвижения, такие дубли только лишнее место занимают, потому что позиция будет или одинаковая или отличаться незначительно. Можно удалить.
- Можно ли использовать подход «1 ключ – 1 страница»?
Нет. Исключение – сайты в микронишах, где большего количества просто нет. Но это редкость. Во всех остальных случаях для каждой посадочной страницы должна быть подобрана группа поисковых запросов.
- Можно ли использовать только ВЧ и СЧ?
Только ВЧ – нет. ВЧ и СЧ – теоретически да, но в этом мало смысла. Дело в том, что попасть в ТОП по СЧ и ВЧ молодому сайту не так уж просто и на это нужно время. Подключив НЧ, вы сможете начать получать трафик гораздо раньше. Этот трафик позволит начать накапливать поведенческие, а их улучшение даст толчок к росту СЧ и ВЧ. Соответственно отказываясь от этого типа запросов, вы усложняете себе работу.
- Ключи для SEO и контекста разные?
Не то, чтобы разные – они отличаются по степени чистки. Если для SEO в одной группе мы оставляем 5-15 ключей, то в одной группе для контекста их могут быть сотни. Здесь уже не убираются запросы с разным порядком слов, с 0 показов и прочие. Оставляют все что релевантно странице. То есть, семантику для SEO из семантики для контекста сделать можно, наоборот – нет, нужен новый сбор. А настраивать контекст под ключи из SEO не эффективно, очень много будет потеряно.
Заключение
Статья получилась объемная и мы разобрали много моментов, но это скорее база. Очень многие вопросы пришлось или сократить до пары предложений или вообще пропустить. Хороший платный софт по возможности обходил стороной. Поэтому, если остались вопросы – пишите в комментариях. А если хотите делегировать сбор семантики нам – можете сделать заказ на этой странице.
Если семантика у вас уже была подобрана, тогда вам больше подойдет статья про анализ семантического ядра.




